
Toward a Knowledge Graph of Cybersecurity Countermeasures
Peter E. Kaloroumakis
The MITRE Corporation
Annapolis Junction, MD
pk@mitre.org
Michael J. Smith
The MITRE Corporation
Annapolis Junction, MD
smithmj@mitre.org
要旨-本稿では、サイバーセキュリティ・ディフェンスに関する正確で曖昧さのない、情報密度の高いナレッジグラフを目指した我々の研究開発について説明します。私たちは、スポンサー企業のプロジェクトにおいて、サイバーセキュリティ・ディフェンスのコンポーネントと能力を識別し、正確に特定できるモデルの必要性に繰り返し遭遇してきました。さらに、ある能力がどのような脅威に対処できるかを知るだけでなく、その脅威が工学的観点からどのように対処され、どのような状況下でその解決策が有効であるかを具体的に知ることが必要です。このナレッジは、運用の有効性や脆弱性を推定し、複数の機能からなる企業向けソリューションを開発するために不可欠なものです。
D3FENDは、こうした繰り返し発生するニーズに対応するため、対策のナレッジベース、より具体的にはナレッジグラフを体系化するフレームワークを構築しました。このグラフには、サイバーセキュリティ・ディフェンスの主要な概念と、それらの概念を互いに結びつけるために必要な関係の両方を定義する、意味論的に厳密な型と関係が含まれています。各概念と関係は、サイバーセキュリティに関する文献の中で特定の文献に基づきます。2001年から2018年にかけて米国特許庁のコーパスから抽出された500以上の対策特許の標的サンプルを含む、研究開発文献の数多くの情報源が分析されました。このアプローチの価値を実際に示すために、サイバーセキュリティ・ディフェンスと攻撃的TTPを推論的にマッピングできるクエリーをグラフがどのようにサポートするかを説明します。より大きなビジョンの一部として、研究文献のリンクされたオープンデータを活用し、機械学習、特に半教師付きメソッドを適用して、D3FENDナレッジグラフを長期的に維持することを支援する、将来のD3FEND作業の概要を説明します。最後に、我々はD3FENDに関するコミュニティのフィードバックを歓迎します。
用語インデックス-対策(countermeasures)、サイバーセキュリティ(cybersecurity)、サイバー防御(cyber defense)、侵入検知(intrusion detection)、知識獲得(knowledge acquisition)、知識工学(knowledge engineering)、ナレッジグラフ(knowledge graph)、リンクトデータ(linked data)、ネットワークセキュリティ(network security)、オントロジー(ontology)、手順(procedures)、戦術(tactics)、手法(techniques)、TTPs(Tactics, Techniques and Procedures)。
米国国防総省から資金提供。公開リリースが承認されました。配布無制限。ケース20-2034。 Copyright 2021 The MITERCorporation. 全著作権所有。
I.はじめに
サイバーセキュリティ・ディフェンス市場は、5,000社以上の企業で構成されています[1]。2018年には、6,000件以上のサイバーセキュリティ特許が出願されています(図1)。また、サイバーディフェンスチームは、ベンダー製品にないものに対応するため、独自の対策を実施しています。これらのカスタム機能は、オープンソースソフトウェアのコミュニティを通じて共有されることが多い。適応のサイクルの中で、急速に変化する攻撃手法に対応する対策が急速に開発されます。
サイバーセキュリティ・ディフェンスとは、攻撃的なサイバー活動を無効化し、相殺するために開発されたプロセスや技術のことです。対策は、何を検知し、何を防ぐのか、ということを理解するだけでは十分ではありません。対策がどのように行われるかを理解する必要があります。セキュリティ・アーキテクトは、自組織の対策について、その内容、方法、および限界を正確に理解する必要があります。セキュリティギャップを特定するための演習を行うレッドチームは、対策を回避するため に、対策の機能に関する専門的な知識を持って対策を計画しなければならない。サイバーセキュリティの新興企業を検討しているベンチャーキャピタルは、その企業が解決しようとしている問題、過去に解決されたことがあるかどうか、どのように解決されたか、提案された解決策がなぜ優れているか、または斬新であるかを理解する必要があります。
既存のサイバーセキュリティ・ナレッジベースは、これらのニーズを満たすためにこれらの対策が何をするのかを十分な忠実度と構造で説明していないため、セクションIIで説明した著名なナレッジベースをレビューしました。さらに、サイバーセキュリティ空間における変化の速度に合わせて、そのナレッジ・コンテンツを持続させたフレームワークやモデルは存在しませんでした。D3FEND™は、対策、その特性、関係、開発の歴史に関するきめ細かなセマンティックモデルを確立しています。また、MITREのATT&CK®フレームワーク[15]の一部の意味モデルを定義し、攻撃的TTPを同じ共通の標準化されたセマンティック・ランゲージ(OWL DL)で表現しています。これにより、ATT&CKの概念をD3FENDの防御技術および成果物のモデルに直接マッピングすることで、ATT&CKを取り込むことが可能になりました。D3FENDは、コンテンツを新しいナレッジにキュレーションし、意味のある方法でそのソース情報と結びつけるための方法論を提供します。最後に、本論文は、有望な人間の言語技術と半教師付き学習を利用・拡張し、業界のペースでコンテンツを収穫・分析するための研究ロードマップを提供します。
D3FENDの長期的な目標は、(1)サイバーセキュリティ・ディフェンス技術を特徴づけ、関連付けるための持続可能なナレッジ・フレームワークを構築すること、(2)サイバー領域における技術変化に対応するために必要なナレッジの発見と獲得の努力を加速させることです。我々が構築したD3FENDナレッジグラフは、Linked Open DataCloud [41]で利用可能な、より大規模なデータセットのウェブに直接埋め込むことができる。これらは、我々のナレッジを研究文献、組織、著者、発明者、投資家に接続するために使用されるでしょう。我々は、選択された表現が、機械学習アプローチを含む自動化を促進する研究のための強力な基盤を提供すると考えている。本論文では、モデルの初期バージョンを作成するために、どのようにデータを収集し、分析したかを説明する。以下のセクションでは、関連する研究、我々の方法論、結果として得られた対策技術のナレッジグラフ、そして最後に今後の研究のロードマップについて述べる。
II. 関連作業
関連する先行研究としては、初期のサイバーセキュリティ標準とフォーマット、政府と民間のサイバーセキュリティ脅威フレームワークとナレッジベース、商用製品分類法、サイバーセキュリティと他のドメインにおける正式な情報モデリングなどがあります。
A. MITREが開始したサイバーセキュリティ標準とフォーマット
過去20年間、MITREはサイバーセキュリティ情報をキャプチャするための標準言語とフォーマットを開発してきました:Common Vulnerabilities and Exposures(CVE®)[2]、Common Weakness Enumeration(CWE™)[3]、 Open Vulnerability and Assessment Language(OVAL®)[4]、Common Platform Enumeration(CPE™)[5]、Common Event Expression(CEE™)[6]、Common Attack Pattern Enumeration and Classification(CAPEC™)[7]、Malware Attribute Enumeration and Characterization(MAEC™)[8]、およびCyber Observables(CybOX™)[9]言語。これらの共有ボキャブラリーと曖昧さ回避のためのリファレンスは、サイバーセキュリティの専門家がサイバー脅威に関するナレッジを記録し、交換するのに役立ちます。 CybOX、MAEC、CAPECは、より分類学的で関係性のある情報を導入し、その要素はサイバー脅威インテリジェンス(CTI)のための構造化脅威情報表現(STIX™)OASIS™標準に取り入れられています。これらは、対策の詳細かつ明確なモデルを構築するための参考となるものです。
B.サイバーセキュリティ脅威フレームワーク
このフレームワークは、組織がサイバーセキュリティのリスクを管理するために、識別-保護-検知-応答-回復のパラダイムを中心にサイバーセキュリティ活動を調整するためのセキュリティガイダンスを提供するものです [10]。このパラダイムは、次に述べるキルチェーンモデルよりも広範ですが、工学や技術よりも、むしろ活動や組織に重点を置いています。NISTはまた、NIST 800-53 [11]に列挙されたセキュリティ対策に関する標準ベースの脆弱性管理データの米国政府リポジトリであるNationalVulnerabilityDatabaseを管理しています。NISTは、これらの関連するセキュリティ制御を、サイバーセキュリティフレームワークで定義された活動にマッピングしています。キルチェーン指向の派生型脅威モデルは、一般的で効果的であることが証明されています。D3FENDのような新しいモデルは、サイバーコミュニティに迅速に受け入れられ、既存のリソースと容易に統合できるように、これらに関連していなければなりません。米国国防総省のサイバー分析とレビュー及び米国国土安全保障省のサイバーセキュリティアーキテクチャレビュー(.govCAR)フレームワークは、サイバー脅威と緩和策のハイレベルな特徴付けのための脅威ベースのツール、及びサイバーポートフォリオとアーキテクチャのギャップを識別する手段として機能します [12]。国家情報長官室は、サイバー脅威の事象を特徴づけ、分類するための共有辞書として機能するサイバー脅威フレームワークを作成しました [13]。国家安全保障局のTechnicalCyber Threat Frameworkは、広範な技術的な詳細を追加しました[14]。MITREのATT&CKは、これらのフレームワークに影響を与え、また影響を受けています。
C. ATT&CK
MITREは、「Finding Cyber Threats with ATT&CK-Based Analytics」において、侵害後の敵の行動を検出することに焦点を当てた分析開発手法を構築しました[15]。これは、セキュリティ専門家が自分たちの仕事を議論するために使用する言葉に革命をもたらしました。ベンダーは、自社製品がどのような具体的な敵対行動を検知、防止、または監視できるかを説明するようになりました。ATT&CK は、主に、戦術的な目標によって構成された攻撃技術によって、敵の行動をモデル化しました。それ以来、ATT&CK は、脅威者のテクニックに関するオンライン・ナレッジベースを蓄積してきました [17]。ATT&CK のナレッジ(STIX を介してエンコードされる)は、D3FEND の特に重要な対極にあるものです。D3FENDは、対策に重点を置いています。この2つは、セクションIV-Eで説明するように関連することができる。Cyber Analytics Repository (CAR) は、MITRE の ATT&CK 作業の主要な成果物でした。CAR は、その CAR データ・モデルで主要なオペレーティング・システムと処理イベントに関連するオブジェクトを識別し [18]、また MITRE が開発した分析をカタログ化し、検出するために設計された特定の ATT&CK 技術にそれらをマッピングしています。D3FENDの初期リリースには、開発されたCAR分析が組み込まれていますが、CARがエンドポイント遠隔測定ソフトウェアからのデータと関連分析をセキュリティオペレーションセンターのオペレーターの観点からモデル化したのに対し、D3FENDはハードウェアまたはソフトウェアエンジニアの観点から対策空間をモデル化しています。したがって、D3FENDの範囲は、サイバーセキュリティ技術空間の範囲によってのみ制限されます。
D.市販製品の分類法
市販の製品分類は、機能よりも形状や購入対象者別に整理されていることが多い。これは、どのベンダーが関連しているかを理解するのに便利ですが、製品がどのように動作し、何をするのかを十分に詳しく説明するものではありません。しかし、それぞれのグループ分けが表す特徴や機能には暗黙の了解がある。サイバーセキュリティのマーケティング用語は、基本的な技術的機能にはわずかな変化しかないにもかかわらず、アナリスト企業が毎年新しい分類を作成するほどのペースで変化しています[19]。特許制度も、技術革新の分類法を提供し、個々の特許に 1 つまたは複数のコードを割り当てています。70,000 のコードからなる国際特許分類システムと,その拡張版である協同特許分類システムは,特許のキュレーションに使用されており,欧州と米国の特許庁によって管理されている.サイバーセキュリティの分野では、分類は広範で分類学的なものに過ぎず、特許で詳述されている技術の主要な属性を説明していないことがよくあります。
E.サイバーセキュリティのドメインナレッジの形式的モデル
サイバーセキュリティの領域を正式にモデル化し、交換と理解の共有のためのナレッジ表現を作成するための多くの取り組みがなされてきた。2007 年、Herzog、Shamehri、Duma は、脅威、資産、対策の型とそれらの間の関係を含む、情報セキュリティの詳細なモデルを作成しました [20]。Fenz、Pruckner、Manutscheriは、1つの標準からより正式なセキュリティモデルへ情報セキュリティナレッジをマッピングするためのガイドラインを作成することによって、これを基にしました[21]。WangとGuoは、CVE、Common Vulnerability Scoring System、CWE、CPE、CAPECを組み込んで、脅威と脆弱性管理のパターンを記述し、推論を行い、ユーザの意思決定を支援するために、脆弱性、製品、対策、アクター間の主要な関係を把握する形式知モデルを作成しました [22]。
2012年、MITREは、一般的なサイバーナレッジモデルと、一連の反復的改善を通じてその中核を拡張する方法を作成する目的で実施されたトレードスタディについて報告しています[23]。このチームは、セキュリティソフトウェア製品間のデータ交換を目的に開発されたMAEC言語とSwimmerの先行マルウェア概念モデルからモデルを構築することに最初の作業を集中させました。ここからObrstらは、より広範なサイバーナレッジ・アーキテクチャのビジョンを提供し、彼らの仕事とアーキテクチャをコンテキスト化するために、サイバー関連のナレッジ表現とスタンダードの有用な調査を提供している。Oltramariらは、サイバーセキュリティ領域における状況認識をサポートするための主要な要素と相互作用のある基本的なアーキテクチャを作成し、次に彼らのアプローチを使用したモデリング例を提供した[24]。Salemらは、運用データを抽出し、多数のソースからのデータをナレッジグラフに統合し、サイバーイベントの原因と影響のリアルタイムな探索を可能にするTAPIOツールを作成しました[25]。
Syedらは、いくつかの既存のナレッジスキーマとスタンダードをサイバーセキュリティ領域の共通モデルに統合することでUnified Cybersecurity Ontology(UCO)モデルを作成し、Oltramariらと同様に彼らのモデルはサイバー状況認識シナリオをサポートしています[26]。2019年、Cyberinvestigation Analysis Standard Expression(CASE)コミュニティは、”デジタルフォレンジック科学、インシデント対応、テロ対策、刑事司法、法医学情報、状況認識などのサイバー調査領域における最も幅広い関心に対応する “コミュニティ開発の仕様言語の調整を目的として結成されました。CASE は UCO と連携し、拡張します。
F.ナレッジグラフとリンクトデータを活用した成功例
近年のナレッジモデリングとリンクデータ技術の進歩により、いくつかのドメインで採用されるようになりました。この技術は、医学、生物科学、バイオインフォマティクスの分野において、医療データセットやゲノムの複雑なパターンをカタログ化し、深く理解するための基礎となることが証明されています。科学者たちは、複雑な化学的およびタンパク質相互作用に関するナレッジを迅速に共有し、共同研究を行うことができるようになった。Unified Medical Language System [27]は213の医学用語を統合している[28]。バイオインフォマティクスの研究者は、The European Molecular Biology Laboratory と European Bioinformatics Institute のオープンデータリソースと、タンパク質配列とアノテーションデータを含む The Universal Protein Resource に含まれるナレッジを利用し、結びつけることができる。Schema.org vocabulary [29]は、Google、Microsoft、Yahoo、Yandexによって設立されたオープンデータコミュニティである。スキーマはコミュニティのプロセスを通じて開発されてきた。Schema.orgはセマンティックウェブの概念に基づいており、構造化されたソーシャルデータを共有することを選択したサイトと、そのソーシャルデータのアグリゲータの間のデータ交換と理解の共有を促進します。GoogleはKnowledge Graph Search APIにschema.orgの型を使用しています[30]。Thomson Reutersもこの技術に投資しており、金融データ [31] とニュース・コンテンツのためのナレッジグラフ・グループを設立しスピンオフしています。D3FENDのナレッジグラフと方法論に直接関係するのは、既存のオープンリンクデータリソースです。特許データ(および特許コーディングシステム)、著者、研究者、発明者、組織など、すぐに利用できる適切なオープンリンクデータを迅速に統合する機会があると考えています。我々は、標準基盤のリンクデータ技術でこれらのオープンリンクデータセットを使用し、参照することにより、D3FENDが強化される可能性があると信じています。
III.方法論
A.フレームワーク、モデル、およびナレッジグラフ
D3FENDを作成するために使用する3つの主要な情報編成アプローチがあります。 「グラフィカルまたはナラティブ形式で、調査する主な事項(主要な要素、構成概念、または変数)とそれらの間の推定される関係を説明する概念フレームワーク」[32]。 「概念的および用語上の混乱を減らし」、コミュニケーション、再利用性、および協力を促進するために使用されるドメインナレッジモデル[33]。最後に、ナレッジの柔軟な表現を提供し、ドメインに関する複雑な機械推論を可能にするナレッジグラフ。
効果的で明確な対策能力仕様の繰り返しの必要性をサポートするために、(1)サイバー対策ドメインのドメインナレッジモデルを組み込んだ概念フレームワークを提供し、(2)フレームワークとモデルを入力してナレッジグラフを完成させることを目指しています。 3)対抗策を、ATT&CKフレームワークの攻撃的な成果物、および構造化されたサイバーナレッジのより大きなドメイン空間に関連付けます。
D3FENDは、主要対策機能と、その機能を効果的に理解してコンテキスト化するために必要なナレッジの関係をモデル化します。対策手法は、ソフトウェアまたはハードウェアコンポーネントを使用して多くの機能を実行します。一部の機能は、敵の行動に直接対抗します。その他は、本質的により管理的であり、主要対策機能をサポートしており、D3FENDの焦点ではありません。
D3FENDは主に、ベンダー固有の用語や専門用語ではなく、抽象的で一般的なセマンティクスに関係しています。ただし、効果的なセマンティクスを選択するには、通常、専門用語の分析が必要です。場合によっては、有用な新しいセマンティクスを作成または定義します。たとえば、D3FENDの場合、最初にMicrosoftの用語「Windowsカーネル」または「WindowsNTカーネル」ではなく、カーネルの抽象的な定義を含めました。これにより、カーネルの概念を「Linuxカーネル」にも適用できるようになりました。必要に応じて、D3FENDユーザーは、特定のOSカーネルをサブクラス化し、それらのパーツの構成(「カーネルモジュール」要素など)によって、カーネルタイプのより具体的な定義でこれを拡張できます。
B.データソース
D3FENDの構築に使用されたデータは、サイバーセキュリティ・ディフェンスを体系的に理解するための新しいアプローチを支えています。研究チームは、文献の研究クレームからボトムアップ方式でモデルを直接開発し、特定の引用を通じて各対策を文献にリンクし、それらをより高いレベルの抽象化に統合しました。特許、既存のナレッジベース、およびその他のデータソースについて説明します。
1)特許:発明者は、防御的なサイバーセキュリティ手法の技術と方法について、毎年何千もの特許出願を行っています。
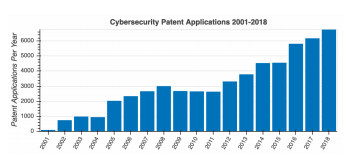
図1.サイバーセキュリティ特許出願2001-2018
2001年から2019年1月までのすべての米国特許庁の出願をダウンロードしました。このコーパス1に対するキーフレーズ検索は、図1のサイバーセキュリティ特許の公開率が増え続けていることを示しています。特許コーパスは、複数の理由から私たちの最初の焦点でした。発明者、投資家、および組織には、サイバーセキュリティ手法が特許でどのように機能するかを説明および区別する強い動機があります。これは、特許が知的財産所有者に提供するさまざまな保護によるものです。また、カテゴリコード、引用、および主張の新規性に関する法的に信頼できる公式の評価を備えた高度にキュレートされたコーパスです。私たちの経験では、ベンダーのホワイトペーパーとマーケティング資料は、手法がエンジニアリングレベルでどのように機能するかを十分に説明しておらず、特許のように統一された方法でも説明していません。現在まで、サイバー対策のナレッジグラフを作成することを目的としたサイバーセキュリティ特許コーパスの包括的な公開分析はないようです。
このコーパスは便利ですが、私たちの目的に使用するときに理解する必要のある多くの問題があります。場合によっては、コーパスは敵対的です。たとえば、学術論文では、研究者が以前の科学的ナレッジを正確に表現するように動機付けられているため、引用は忠実度が高い傾向があります。特許には、引用や先行技術の列挙もあります。ただし、これらは、新しい特許が真に新規で、有用であり、ビジネス目的で自明ではないというケースを裏付けるために選択されることがよくあります。これは、学界で使用されるピアレビュープロセスなしで行われます。
米国特許発明の40%は使用されていません。これらの約半分は、競合他社をブロックすること、または企業間交渉で交渉チップとして使用することを目的とした特許です[36]。私たちの研究は、まだ実践されているかどうかにかかわらず、すべてのサイバー防衛アプローチをカタログ化しています。 D3FENDナレッジグラフを使用すると、実践されていないアプローチが特定され、そのカテゴリのイノベーションと製品化が促進される可能性があります。さらに、私たちの調査は新興分野における最近の発明に焦点を合わせているため、「使用されていない」区別は多くの場合一時的なものです。
1Apache Solrの検索用語:”information assurance” ”cyber security” ”cybersecurity” ”infosec” ”information security” ”network security” ”computer security” ”computer network defense” ”network defense” ”malware” ”computer hacking” ”computer virus” ”data exfiltration” ”cyber warfare” ”information warfare” ”intrusion detection” ”intrusion prevention” ”indicators of compromise” ”security information events” ”cryptographic” ”cryptography”
2)既存のナレッジベース:MITREを分析しました。
Cyber Analytic Repository [34]を作成し、その分析をD3FENDのアルファ版にマッピングしました。リポジトリには、主にエンドポイントテレメトリを使用する検出分析が含まれています。また、セクションIV-Eで説明したように、ATT&CKナレッジベースを分析し、それをD3FENDに関連付ける方法を開発しました。
3)その他のデータソース:その他のデータソースも分析しました。
これらのソースには、学術論文、技術仕様、および公開されている製品の技術ドキュメントが含まれます。
4)主な調査結果:これらのデータソースを確認した結果、これらの利用可能な知的財産文書がサイバーセキュリティ・ディフェンスのナレッジグラフの基盤として役立つ可能性があると判断しました。
また、結果として得られるナレッジグラフが一貫性があり、サイバーセキュリティアーキテクトにとって役立つことを期待していました。 D3FENDナレッジグラフは、主にその範囲、特異性、および可用性のために、特許コーパスから作成されました。これらのデータソースは、さまざまな形式や場所で公開または出版されています。サイバーセキュリティコミュニティには、技術者から学者まで、さまざまな参加者グループがいます。知的財産は、参加者の全範囲によって開発されています。データソースの例が示されています
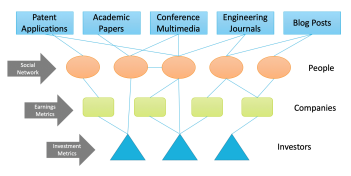
図2.知的財産開発ネットワークの例
この図2.は、サイバーセキュリティ・ディフェンス手法を生み出す知的財産開発ネットワークも示しています。また、これらのデータセットは大きすぎて完全に手動で分析できないことも確認しました。ただし、自動化された手段をより適切に開発できるように、手動分析プロセスから始めました。
C.対策分析プロセス
私たちの最初のアプローチには、自然言語処理技術を使用して、主に米国特許出願である文書で主張されている技術を整理、要約、および分類するためのいくつかの予備的な取り組みが含まれていました。教師なしトピックモデリングとテキスト要約アルゴリズムを実験しました。これらの予備的な方法では、最初にサイバーセキュリティの実践者に役立つセマンティック表現を作成するには不十分であると判断しました。教師ありおよび半教師ありの機械学習アプローチは試行されませんでした。これは、対策またはアーティファクト分類システムまたは一連の決まった用語がまだなく、ラベル付きのトレーニングデータを提供できなかったためです。既存のハイレベルモデルを使用して特定の対策にトップダウンで取り組む、または対策インスタンスの列挙がない独自の高レベルモデルを提案するという初期の取り組みは、概念とセマンティックの望ましいフレームワークを作成するための効果的なアプローチではありませんでした。私たちの経験では、フレームワークを最初から特定のインスタンスに固定しないと、セマンティックのチームコンセンサスを確立することは困難であり、主観的すぎて、個々の寄稿者の経験や背景に偏っていると見なされていました。この経験を踏まえて、特定のテクノロジーの説明に焦点を当て、元の参照に直接リンクされているセマンティック抽象化の階層を構築して、ナレッジグラフの忠実度を高めました。
自動化を念頭に置いて、知的財産文書に含まれる防御手法を説明するセマンティクスを手動で分析、要約、および定式化し始めました。次に、分析をデータベースに記録し、新しいラベル付きデータセットを作成しました。これにより、対策手法のセマンティックと、概念が説明されているソースドキュメントへの参照を含むデータベースが作成されました。このプロセスは、対象分野の専門知識に依存しており、労力を要しましたが、対策スペースの初期セマンティックモデルを開発するために必要でした。さらに、これらの分析を使用してトレーニングアルゴリズムを研究し、初期モデルを改良し、新しい対策手法の開発と認識を促進する予定です。
チームは、複数の基準に基づいて選択された500以上のサイバーセキュリティ特許をレビューし、かなりの技術的詳細でそれらを分析しました。チームはドメインに精通していたため、当初は「検出」指向のベンダーに焦点を合わせました。 IDCのWorldwideCybersecurity Products Taxonomy、2019 [19]からベンダーを選択し、それらの特許を分析しました。これらのテクノロジーの中には、不正なアクティビティを検出するだけではありません。これらの追加の手法を組み込み、D3FENDナレッジグラフに分類しました。
対策活動を中心に問題に取り組みました。システムアクティビティを記述および理解するために、2つの関連するシステムエンジニアリングアプローチを利用しました。アクティビティモデル[38] [39]とユースケース[40]です。これらのアプローチは、防御手法であるという観点から知的財産を検討する際に、知的財産の重要な側面を把握するために、2つの関連する一連の質問を組み立てるのに役立ちました。最初のセットは主要機能アクティビティをキャプチャすることを目的とし、2番目のセットは主要なユーザーインタラクションの側面をキャプチャしました。両方のセットを表Iに示します。
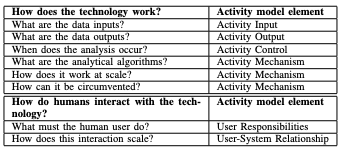
表I. 誘発技法による質問
サイバーセキュリティデータの量と、ユーザーが意思決定ループ内または意思決定ループにとどまる(つまり、システムアラートを監視および処理する)という潜在的な要求を考慮して、基本機能の実装とその結果としてのユーザーインタラクションの両方において、スケーリングの懸念に特に重点を置きました。
チームは、これには時間がかかりすぎることにすぐに気付き、多くの場合、各知的財産文書のすべての質問に答えることはできませんでした。さらに、多くのテクノロジーが複数の問題を解決しました。つまり、複数のD3FENDテクノロジーが含まれていました。その後、新しいアプローチでプロセスを改善しました。
テクノロジーへのデータ入力タイプが、テクノロジーがどのように機能するかを理解し、それらを防御手法に固定するための重要な要素であることに気づきました。 MITERによる以前の作業では、オブジェクトの列挙に関する分析の開発に焦点が当てられていましたが、列挙の範囲は、対策範囲全体ではなくプロセスオブジェクトに焦点が当てられていました[18]。これにより、D3FENDデジタルアーティファクトオントロジーを作成して、これらのデータ入力タイプをより高い特異性で定義することになりました。
この概念については、セクションIV-Eで詳しく説明します。これらの分析中に抽出されたナレッジと事実は、D3FENDナレッジグラフに記録されます。可能な場合は、特定のテクノロジーまたはD3FEND手法に関するこれらの最初の質問のいくつかに回答しました。現在のナレッジグラフはアルファレベルです。一般の視聴者に役立つために必要な機能と情報を追加しています。ロードマップのセクションでは、フィーチャーコンプリートのベータリリースを開発するための計画について説明します。
IV. D3FENDモデル
私たちの方法論では、防御的なサイバーセキュリティテクノロジーがどのように機能するかを分析しました。セマンティックパターンや構造は、クリティカルマスを超えるまで分析した後に現れ始めました。次に、ナレッジが増えるにつれて、この構造を整理して改良しました。 「D3FEND」とは、ナレッジグラフ、ナレッジグラフのユーザーインターフェース、ナレッジモデルなど、D3FENDのすべてのコンポーネントを指します。
A.構造の概要
D3FENDナレッジグラフのユーザーインターフェイス(図3)は、階層も考慮した表形式のビューで防御的な戦術と手法を提供します。 モデルのこのビューは、有向非巡回グラフとして表されます。 各要素は、より詳細な情報にリンクしています。 D3FENDナレッジモデルには、図4に示すように、いくつかの主要なトップレベルの概念があります。型の階層は金色の矢印で示され、これらの主要概念間の基本的な関係は青い線で示されます。 この主要部は、概念のインスタンスを配置し、D3FENDナレッジグラフを構成するリレーショナルアサーションを編成するために使用されます。

図3.D3FENDナレッジグラフのユーザーインターフェイス:戦術と手法の概要
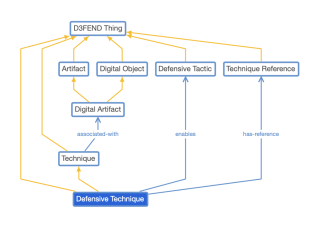
図4.D3FEND主要ナレッジモデル
現在開発中のD3FENDナレッジグラフは、特定のタイプのナレッジベースです。 concepFigを接続します。 4.特定の事実に対するD3FEND主要ナレッジモデルのチュアルモデル(つまり、ナレッジモデル)。これはインスタンスと、それらの関係およびタイプを表すグラフ構造です。
B. D3FEND手法セマンティクス
D3FEND手法は、D3FENDナレッジモデルの中心的かつ最も重要な概念です。それらはD3FEND技術研究者によってキュレーションされています。サイバーセキュリティ技術は複雑になる可能性があり、複数のD3FEND手法で構成される場合があります。意味的には、D3FEND手法は、重要な情報を取得する簡潔なフレーズとして表されます。これは高次元の最適化問題であるため、実行するのは困難です。
用語は、最大限の情報と最小限の混乱のために選択されています。サイバーセキュリティは学際的な分野です。これには、技術研究者が主要なサイバーセキュリティドメインだけでなく、コンピュータサイエンスとアーキテクチャ、データ分析、社会科学、情報技術アーキテクチャなどの隣接するドメインにも精通している必要があります。 D3FEND技術研究者は、最適で正確かつ正確な用語を選択するために、さまざまな技術的背景を持つ人々が持つ可能性のある多数の解釈を予測する必要があります。一般に、コンピュータサイエンスおよびコンピュータエンジニアリングドメインのセマンティックコンテキストは、他のドメインよりも優先されます。
C. 手法の例:プロセスコードセグメントの検証
D3FENDで使用される主要コンセプトをよりよく説明するために、開発プロセスで発見されたD3FEND手法の例(プロセスコードセグメントの検証)について説明します。ここでは、それらの単語が選択された理由、それらの意味、およびそれらと結果のナレッジグラフエントリによってユーザーが実行できることについて説明します。
私たちの方法論を使用して、さまざまなサイバーセキュリティベンダーから公開されている何百もの知的財産を特定して分析し、D3FEND手法を抽出しました。
これらの手法を意味的にグループ化して説明し始めました。
プロセスコードセグメントの検証の場合、複数のベンダーが同じ技術的な問題を非常に異なる方法で解決しようとしていると判断しました。これらのテクノロジーは20年以上にわたって開発され、エンドポイントソフトウェアエージェントからソフトウェアコンパイラテクノロジーに至るまで、根本的に異なるフォームファクターで展開されました。さらに、検証に対する彼らの分析的アプローチは異なっていました。さまざまなアプローチには長所と短所があることは明らかでした。大きな違いはありますが、これらのテクノロジは同じ問題を解決するように設計されています。実行中のプロセス内のコードセグメント(テキストセグメントとも呼ばれます-図5)が期待どおりであることを確認します。
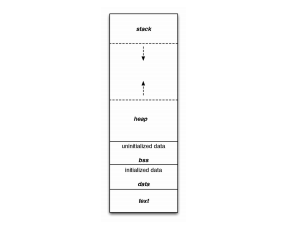
図5.コード(テキスト)セグメントとプロセスメモリレイアウト[37]
製品が特定の手法を実装していると正確に主張するには、その手法のセマンティクスを理解する必要があります。プロセスコードセグメントという用語は、実行中のプロセスに割り当てられた、実行用のマシンコードを含むメモリの部分を意味するように定義されています。これらのコードセグメントは通常、アプリケーションを実行してプロセスを起動するときにディスクからロードされます。プロセスコードセグメントを指定することにより、この手法はディスク上のアプリケーションイメージではなく、起動されたプロセスのメモリにロードされた後の状態に関係することを説明します。検証は、コードセグメントの整合性だけでなく、検証するための真実のソースが存在することを示唆しています。この手法名は、コンピュータサイエンスの領域に由来しています。コードセグメントという用語は、実行可能ファイルのマシンコード部分を説明するために多くのコンピュータサイエンスの教科書で使用されています。
手法名の質を客観的に定量化するには、追加の研究が必要です。
特定のD3FEND手法を理解するためのセマンティックができたので、ベンダーに重要な質問をすることができます。どのような状況で、テクノロジーはプロセスコードセグメントを読み取って検証しますか?コードセグメントの検証に使用される信頼できる情報源は何ですか。被害者のマシンまたはリモートシステムにありますか?コードセグメントが無効であると判断された場合はどうなりますか?これらの質問への回答は興味深く、サイバーセキュリティ技術開発者の創造性と巧妙さを示しています。
このナレッジ、知的財産の参照、および分析は、プロセスコードセグメント検証の手法の下でD3FENDナレッジグラフに記録されました。この情報を整理し、知的財産をカタログ化することで、専門家は手法がどのように機能するかを理解できるだけでなく、どのアプローチが彼らの固有の要件により適しているかを考えることができるようになりました。
この例(プロセスコードセグメントの検証)は、セマンティックの特異性の2つの主要な次元内での位置付けを示しています(図6)。
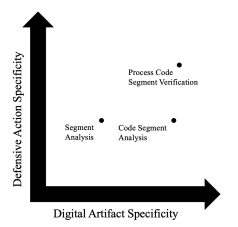
図6.セマンティック特異性の主要な側面
機能の記述に必要な特異性のレベルは、使用状況によって異なります。
私たちの分類学的アプローチは、さまざまなレベルの特異性に対応しています。これにより、モデルを特定のユースケースに合わせて簡単に調整できます。たとえば、買収アナリストはより一般化する必要があるかもしれませんが、エンジニアはより具体的に要求するかもしれません。
D. D3FENDの戦術と手法
D3FENDナレッジグラフで手法を開発する際に、共通の関係を持つ同様の手法のセットを特定しました。たとえば、一部の手法は主に生のネットワークトラフィックを分析しますが、他の手法は純粋にプロセス分析に焦点を合わせます。次に、これらの手法は自然にさらにグループ化され、より一般的なタイプの手法が編成されます。
トップレベルの手法を基本手法として区別し、そこから他のすべての手法が派生します。たとえば、手法手順コードセグメントの検証は、基本手法「プロセス分析」に分類されます。手法をグループ化するときに、別のより高いレベルの概念である防御戦術を特定しました。防御戦術は、D3FENDナレッジグラフで最も一般的な編成クラスです。図4を参照してください。防御戦術は、敵の行動に応じた作戦です。これらは、複数の手法を一般化するためにアクション指向で慎重に選択された用語です。
私たちが特定した防御戦術の例は、Detect、Harden、Deceive、Evict、Isolateです。戦術は一番上の行に示され、基本的な手法は図3の2番目の行に示されています。より具体的な防御手法は、基本手法の下の列に表示されます。手法は1つの基本手法にのみ属します。一般に、手法は最も一般的なものから最も具体的なものへの階層を形成します。わかりやすくするために、防御手法の階層の2つのレベルのみを図3に示します。
最後に、個々の手法の丸で囲んだ数字は、手法を開発するために分析されたソースドキュメントの数を表しています。
状態の暗黙の概念は、戦術のために選択された用語で表現されます。防御側は、敵を検出できない場合は敵を追い出すことができず、敵がいない場合は敵を検出できません。理想的には、防御側は敵が侵入する前に環境を強化します。
戦術とは、防御側が敵に対して行う操作、つまりアクションの“the what” です。手法は、これらのアクションを採用するために使用される方法、つまり戦術を実装する“the how”です。これらの戦術は手法によって可能になると言えます。
E.デジタルオブジェクト、デジタルアーティファクト、および手法マッピング
D3FENDの重要な構成要素は、デジタルアーティファクトオントロジー(DAO)です。このオントロジーは、サイバーセキュリティ分析の対象となるデジタルオブジェクトを分類および表現するために必要な概念を指定します。 D3FENDナレッジモデルでは、図7.デジタルアーティファクトを介した攻撃的および防御的手法のマッピングデジタルオブジェクトは、防御的または攻撃的のいずれかのサイバー攻撃者が何らかの方法でオブジェクトと対話すると、デジタルアーティファクトになります。合理的なモデリング範囲を確保するために、D3FENDナレッジモデルは、既知のサイバーアクターおよび既知のテクノロジーに関連するデジタルアーティファクトに関するナレッジのキャプチャのみに関係します。すべての可能なデジタルオブジェクトまたはその表現ではありません。
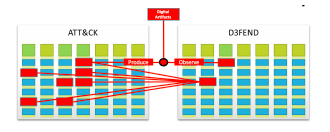
図7.デジタルアーティファクトを介した攻撃的および防御的手法のマッピング
この分野の関連作業では、サイバー防御操作で使用される一般的な概念をリストして定義するためのセマンティックが開発されました。
これらのセマンティックのいくつかの制限は、D3FEND DAOの構築を動機付けました。これらのセマンティックは、セマンティックではなく構文であることが多く、ベンダー固有の概念が含まれ、列挙型と分類型であったためです。さらに、これらのセマンティックは概念間の関係を指定していませんでした。最後に、彼らの範囲は、セキュリティ運用とインシデント対応と機能エンジニアリングでした。したがって、D3FEND DAOをより抽象的なセマンティック構造として開発し、表現を統合し、ベンダーにとらわれない推論を可能にする必要がありました。
アーティファクトという用語は、考古学的な意味で選択されました(たとえば、一部の人間はアーティファクトをどこかに置きました)。それが何らかのデジタル形式で、あるコンピューター上に存在しない場合、それはオントロジーの範囲外です。
デジタルアーティファクトは、観察可能またはアクセス可能である必要はありませんが、存在する可能性があります。アーティファクトは他のアーティファクトを含むこともあり、したがって複合アーティファクトの表現を可能にします。図8を参照してください。
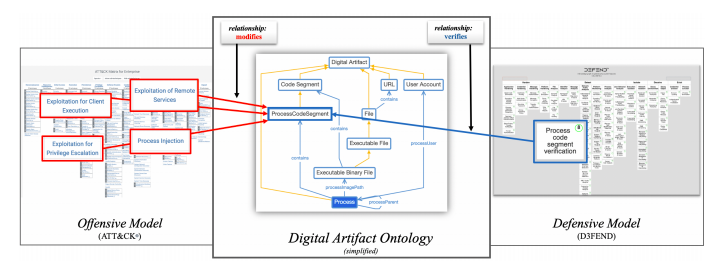
図8.デジタルアーティファクトオントロジーによる推論によるマッピング
デジタルアーティファクトは、D3FENDナレッジモデルの概念的な範囲も確立します。たとえば、強力なパスワードポリシーは、組織のテクノロジー構成ベースラインに直接影響するため、範囲内にあります。したがって、デジタルアーティファクトが含まれます。反例として、多くの組織が従業員のサイバーセキュリティ意識向上トレーニングプログラムに投資しています。トレーニングプログラムはデジタルアーティファクトと直接相互作用しないため、対象外です。
攻撃者がキーボードで入力してオープンソースのインターネット調査を実行すると、デジタルアーティファクトが生成されます。ソフトウェアエクスプロイトを開発したり、悪意のあるフィッシングリンクを送信したり、ターゲットの環境でリモート制御されたホストを操作したりするとき、彼は自分のシステム、中間システム、およびターゲットシステムの両方でデジタルアーティファクトを作成します。防御側の攻撃者が攻撃者のデジタルアーティファクトを観察できるかどうかは、攻撃者の視点と能力によって異なります。図7は、攻撃的手法と防御的手法の間のこれらの相互作用を簡略化して示しています。
サイバーセキュリティアナリストは、サイバー攻撃がサイバー防御によってどのようにカバーされているか、またはその逆を知る必要があります。したがって、これら2つの間の関連付けを詳細に指定するための合理的なメカニズムが必要です。私たちのアプローチは、関係を概念化してインスタンス化するための基礎としてデジタルアーティファクトを使用することに焦点を当てています。攻撃的手法と防御的手法の両方がデジタルアーティファクトに関連付けられており、関連付けられているのは、生成、実行、分析、アクセス、およびインストールのより具体的な関係の一般的な関係タイプです。 D3FENDナレッジモデルは、攻撃的手法と防御的手法の間のより具体的な関係タイプもサポートします。たとえば、監視、検出、カウンターなどです。
この階層化されたアプローチの主な利点は、各手法がデジタルアーティファクトにどのように関連しているかを分析することにより、攻撃的手法と防御的手法の関係について推論できることです。
これにより、攻撃的な手法を防御的な手法に手動で直接関連付ける必要はなく、これらの特定のタイプの関係を推測できます(図8)。攻撃的手法、防御的手法、デジタルアーティファクトに関するナレッジをそれぞれ個別に正確に表現すれば、明示的な列挙が必要となる推論を通じてナレッジを蓄積し、追加のナレッジと洞察を引き出すことができます。
アーティファクトは階層的な分類によって特徴が定義され、それらの包摂関係は図8の金色の線で表されます。
Linuxサービスデーモンの構成ファイルは、システム構成ファイルでもあるサービス構成ファイルです。これは構成ファイルのファイルであり、ファイルは最上位で最も具体性の低い概念です。これにより、「どの防御手法がファイルに関連付けられているか」などの一般的な質問をする能力を維持しながら、または「デーモン構成ファイルに関連付けられている防御手法はどれか」などのより具体的な質問。特定の防御手法が関連付けられているアーティファクトを可能な限り具体的に確認できます。
V.ロードマップ
D3FENDプロジェクトには、3つのロードマップの重点分野があります。実践者向けのモデルユーティリティの改善とデモンストレーション、分析によるモデルの深化と拡大、業界の変化に応じたモデルの更新です。
A.モデルユーティリティ
セマンティックモデルは、採用されたときに最も役立ちます。彼らは共通の言語を作成します。このモデルは、サイバーセキュリティアーキテクトやエンジニアによる実際のユースケースで使用します。モデルの成功は専門家の採用と複数のユースケースにわたる有用性についての前向きなコンセンサスです。
採用の獲得には、モデルを使用して有用性を定性的に評価し、改善を行う反復プロセスになります。
1つの評価では、このモデルを使用してサイバーセキュリティ製品を区別および分析します。大規模な組織は、テクノロジーベンダーから多くのインバウンドリクエストを受け取ります。 D3FENDが製品が提供する特定の機能を明確にし、ベンダーのマーケティング資料の分析に費やす時間を削減することを願っています。別の評価では、コンピュータネットワークの既存の対策を分析し、どの防御手法が存在するかを特定します。まず、幅優先分析として、サイバーセキュリティアーキテクトに基本技術に関連するテクノロジーを尋ねます。これにより、機能のギャップや重複が特定されることを願っています。
ユースケースを進めながら、使用されたモデルの量と追加された新しい手法の数を追跡します。私たちの仮説は、セマンティックの再利用は時間の経過とともに増加し、最終的にはモデルへの追加の頻度を減らすというものです。この予備的なペーパーを、1つ以上の特定の機能分析シナリオへのD3FENDの適用に関する詳細を提供するものでまもなくフォローアップする予定です。
B.モデルの深さ、幅、および技術開発
ナレッジグラフを成長させるには、より多くの知的財産を分析する必要があります。 増え続けるデータセットのサイズのため、分析プロセスの一部を自動化する必要があります。 これには、ナレッジの抽出、新しいトピックの検索、古いトピックの追跡を支援できるツールのシステムが必要です。 このシステムを使用して、機械学習アルゴリズムがナレッジグラフのデータを処理し、ナレッジグラフと潜在的に新しいナレッジのインスタンスを特徴付けるモデルを開発できるようにする方法を検討します。 新しいデータに自動的にタグを付けることにより、
対抗策の分野で新しい概念や用語の発見を促進することができます。 これを支えるために、公開データを取り込み、新しいナレッジを取得し、高度な検索メカニズムおよびストレージをサポートする柔軟なナレッジグラフ・アーキテクチャを開発します。
1)将来のデータソースと知的財産生成ネットワーク:知的財産は多くのソースから収集できます。図2に示すように、アクター(人、企業、投資家)の頂点、それらの間の関係のエッジを含むグラフを作成し、ビジネスまたは影響のメトリックでエッジを重み付けすることにより、知的財産の潜在的な関連性または価値を推定する予定です。学術論文、会議のプレゼンテーション、ブログなど、追加の技術コーパスに特許の分析に使用したのと同じ方法論をセクションIIIで適用することを期待しています。投稿、およびエンジニアリングジャーナル。これらのデータソースはテキストベースの表現に縮小され、自然言語処理技術による分析を加速できるようになります。
C.モデルの更新
特許出願の提出率の分析で示されているように、サイバーセキュリティ市場には大きなダイナミズムと活動があります。 公共の知的財産の新しい情報源が収集されると、それらをアーカイブ、処理、および分析する必要があります。 私たちのナレッジグラフツールは、新しいデジタルアーティファクトと新しい防御手法を発見します。 これらの発見は、D3FENDナレッジグラフに追加されます。
VI. 結論
D3FENDでは、サイバーセキュリティ・ディフェンスに関する正確なセマンティックモデルを作成しました。これにより、実務者は初めて、技術能力に関する工学レベルの知識で防御を評価し、ギャップを埋めることができるようになりました。D3FENDのアルファ版(図3)は、MITREのサイバーセキュリティ専門家から好評を博しました。さらなる検証のためには、対策要求分析での成功が必要です。新しい防御技術を繰り返し追加することが容易であったため、その意味的な一貫性に満足しました。これらの初期結果は有望であり、我々の研究は実世界のデータソースから構築された対策モデルの実現可能性を示したと考える。次の段階では、このモデルに対策を完全に盛り込み、常に最新の状態に保つために必要なツールを開発することに重点を置く予定です。この分野の変化のスピードに対応し、D3FENDの対策ナレッジグラフを長期的に維持するためには、自動化が必要です。
謝辞
この作業に貢献してくれたMITREの仲間と従業員に感謝します。
Greg Dunn, Chris, Thorpe, Jay Vora, Maura Tennor, Joe Patrick, Drew Cannon, Chris Magrin, Matt Venhaus, Emily Hopkins, Zach Asher, Parker Garrison, Robert Heinemann, Dan Ellis, Steve Luke, and Bonnie Martin.
引用元
[1] Crunchbase Inc., “Companies — Crunchbase” 29 October 2019.
[2] The MITRE Corporation, “Common Vulnerabilities and Exposures,”
1999.
[3] The MITRE Corporation, “Common Weakness Enumeration,” 1999.
[4] The MITRE Corporation, “Open Vulnerability and Assessment Language,” 2002.
[5] The MITRE Corporation, “Common Platform Enumeration,” 2007.
[6] The MITRE Corporation, “Common Event Expression,” 2007.
[7] The MITRE Corporation, “Common Attack Pattern Enumeration and
Classification,” 2007.
[8] The MITRE Corporation, “Malware Attribute Enumeration and Characterization,” 2011.
[9] The MITRE Corporation, “Cyber Observable eXpression (CybOX™)
Archive Website,” 2012.
[10] NIST, “Framework for Improving Critical Infrastructure Cybersecurity,”
April 2018.
[11] NIST, “NIST Special Publication 800–53 Revision 4: Security and
Privacy Controls for Federal Information Systems and Organizations,”
NIST, 2015.
[12] Department of Homeland Security, “DoDCAR/.govCAR,” 2018.
[13] J. Richberg, “A Common Cyber Threat Framework: A Foundation for
Communication,” 2018.
[14] NSA Cybersecurity Operations, The Cybersecurity Products and Sharing Division, “NSA/CSS Technical Cyber Threat Framework v2,”
NSA/CSS, Fort Meade, MD, 2019.
[15] B. E. Strom, J. A. Battaglia, M. S. Kemmerer, W. Kupersanin, D. P.
Miller, C. Wampler, S. M. Whitley, R. D. Wolf, “Finding Cyber Threats
with ATT&CK™-Based Analytics,” 2017.
[16] B. E. Strom, A. Applebaum, D. P. Miller, K. C. Nickels, A. G.
Pennington, and C. B. Thomas, “MITRE ATT&CK™ Design and
Philosophy,” 2018.
[17] The MITRE Corporation, “MITRE ATT&CK™,” 30 October 2019.
[18] The MITRE Corporation, “CAR Data Model,” 30 October 2019.
[19] International Data Corporation, “IDC’s Worldwide Cybersecurity Products Taxonomy, 2019,” 2019.
[20] A. Herzog, N. Shamehri, and C. Duma, “An Ontology of Information
Security,” in International Journal of Information Security and Privacy,
2007.
[21] S. Fenz, T. Pruckner, and A. Manutscheri, “Ontological Mapping of
Information Security Best-Practice Guidelines,” in Business Information
Systems: 12th International Conference, Poznan, Poland, 2009.
[22] J. A. Wang and M. Guo, “OVM: An Ontology for Vulnerability
Management,” in CSIIRW, Oak Ridge, Tennessee, 2009.
[23] L. Obrst, P. Chase, and R. Markeloff, “Developing an Ontology of
the Cyber Security Domain,” in Semantic Technology for Intelligence,
Defense, and Security (STIDS), Fairfax, Virginia, 2012.
[24] A. Oltramari, L. F. Cranor, R. Walls, and P. McDaniel, “Building an
Ontology Of Cyber Security,” in STIDS, Fairfax, Virginia, 2014.
[25] M. B. Salem and C. Wacek, “Enabling New Technologies for Cyber
Security Defense with the ICAS Cyber Security Ontology,” in STIDS,
Fairfax, Virginia, 2015.
[26] Z. Syed, A. Padia, T. Finin, L. Mathews, and A. Joshi, “UCO: A
Unified Cyber Ontology,” in AAAI Workshop on Artificial Intelligence
for Cybersecurity, Phoenix, Arizona, 2016.
[27] O. Bodenreider, “Unified Medical Language System (UMLS): integrating biomedical terminology,” Nucleic Acids Res., vol. DB, no. 32, pp.
267–270, 23 May 2004.
[28] NIH, “UMLS Metathesaurus Vocabulary Documentation,” NIH U.S.
National Library of Medicine, 4 November 2018.
[29] Schema.org Community Group, “schema.org,” Schema.org Community
Group, 2015.
[30] Google, “Google Knowledge Graph Search API,” Google, 2019.
[31] Refinitiv, “Knowledge Graph feed BETA,” 2019.
[32] M. B. Miles and A. M. Huberman, “Qualitative Data Analysis: An
Expanded Sourcebook,” Thousand Oaks, CA: Sage Publications, 1994.
[33] M. Missikoff, P. Velardi, and P. Fabriani, “Text Mining Techniques to
Automatically Enrich a Domain Ontology,” Applied Intelligence, vol. 3,
no. 18, pp. 323–350, 2003.
[34] The MITRE Corporation, “MITRE Cyber Analytics Repository”
[35] R. Bretnor, “Decisive Warfare: A Study in Military Theory,” in Decisive
Warfare: A Study in Military Theory (New ed.)., Wildside Press LLC.,
February 1, 2001, p. 49–52.
[36] P. Zuniga, D. Guellec, et al. “OECD patent statistics manual,” Paris:
OECD Publications, 2009
[37] Wikipedia contributors, “Organization of
a program into segments,” Available:
https://en.wikipedia.org/wiki/File:Program memory layout.pdf,
November, 2019.
[38] D. Ross, “Structured Analysis: A Language for Communicating Ideas,”
IEEE Transactions on Software Engineering 3(1), Special Issue on
Requirements Analysis, January 1977, 16-34.
[39] Defense Acquisition University Press, ”System Engineering Fundamentals,” Fort Belvoir, VA, January, 2001.
[40] I. Jacobson, M. Christerson, P. Jonsson, and G. Overgaard, “Objectoriented software engineering – a use case driven approach,” AddisonWesley 1992, ISBN 978-0-201-54435-0, pp. I-XX, 1-524.
[41] J. McCrae, “The Linked Open Data Cloud”, iod-cloud.net, https://iodcloud.net, Accessed on: 2020-08-25.