
Hardening Designers Conference 2023 – 人とAIが協調するシフトレフト –
ChatGPTから垣間見えた私達と未来のAIについて、Hardening Designers Conference 2023 に登壇しました。
タイトル「ChatGPTに脆弱性診断をやらせてみた」
ChatGPTから垣間見えた私達と未来のAIについて
ここでChatGPTを利用したセキュリティ診断の内製化3つのメリットと「人とAIが協調するシフトレフト」についてお伝え致しました。ありがとうございました。
サイバーエージェント日本語LLMを公開
日本もOpenAIのように、民間の力でイノベーションを起こせるエコシステムが生まれることを願っております。
当社が開発した「最大68億パラメータの日本語LLM」を商用利用可能なライセンスで公開いたしました。本モデルをベースにチューニングを行うことで、対話型AI等の開発が可能です。
— サイバーエージェント 広報&IR担当 (@CyberAgent_PR) May 17, 2023
今後もモデル公開や産学連携を通し、国内における自然言語処理技術の発展に貢献してまいります。https://t.co/BYbcZYFvBi
スーパーコンピュータ富岳
東京工業大学、東北大学、富士通株式会社、理化学研究所は、スーパーコンピュータ「富岳」を活用した大規模言語モデルの分散並列学習手法の研究開発を2023年5月から開始。ものづくりをはじめとする産業分野などへの応用を想定したマルチモーダル化のためのデータ生成手法および学習手法の開発を行う名古屋大学や、大規模言語モデル構築のためのデータおよび技術提供を行う株式会社サイバーエージェントとの連携も今後検討していきます。
東京工業大学、東北大学、富士通株式会社、理化学研究所は、「富岳」政策対応枠において、スーパーコンピュータ「富岳」(以下、「富岳」という)を活用した大規模言語モデル(Large Language Model, LLM)[用語1]の分散並列学習手法の研究開発を2023年5月から実施します。https://t.co/ORj159y4xc
— Satoshi Matsuoka (@ProfMatsuoka) May 22, 2023
APACにおける最大の悪性DNSトラフィック
最新の脅威レポート「SOTI インターネットの現状 | 攻撃の『高速道路』悪性DNSトラフィックの詳細な分析」を発表、Akamaiによると悪性のドメイン・ネーム・システム(DNS)トラフィックがアジア太平洋地域の事業者と消費者にもたらしている脅威を取り上げています。
Akamai脅威レポート:APACにおける最大の悪性DNSトラフィックがQSnatch感染であることを観測
Cloudflare radarのChatGPT Pluginで日本へのDDoS攻撃の状況について確認
まだ英語のみ対応となっておりますが、Cloudflare Radarを利用したリアルタイムのインターネット パターンについて ChatGPT と会話できます。試しに日本へのDDoS攻撃の状況について確認してみました。

ChatGPTの新しいBeta features – Web Browsingで海外の最新のセキュリティーニュースを日本語でチェック
ChatGPTの新しいBeta features – Web Browsingを試してみました。海外の最新のセキュリティーニュースを日本語でチェックすることや、記事のリンクもついておりますので、気になる記事を辿ることも可能です。
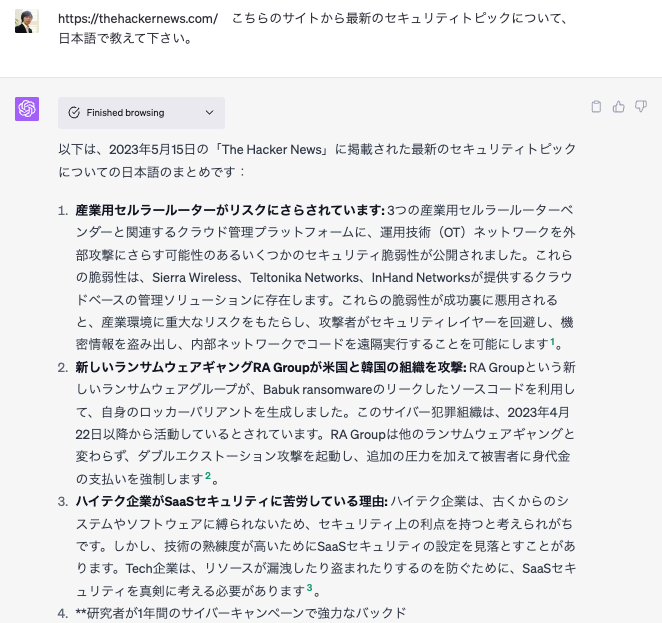
このようなChatGPTの最新情報について、こちらのサイトをおすすめいたします。
Cloudflare Developper Week 2023
プログラマーの定義が変わる…。
・自然言語によるプログラムの記述
・ソースコードに変換される。
・そして全世界の接続された人口の95%で50ms以内にデプロイされる。
GPT-4とCloudflare Workersを使ったサーバーレスAPIの書き方&改善方法
here's an exploration for writing & refining a serverless api using gpt-4 and @cloudflare workers
— harley turan (@hturan) May 15, 2023
🌱a natural language description of a program
🌿transformed into valid source code
🪴and deployed to within 50ms of 95% of the world's connected population
all within 30 seconds pic.twitter.com/3KZQ3Z1Fo1
『うまい、やすい、はやい』24時間働くAIドリブンな企業が台頭
知的集約型産業へのインパクト、近いうちに『うまい、やすい、はやい』24時間働くAIドリブンな企業が台頭する。
技術と経験を集結して、生き残りを賭けた競争が始まります。今までのDXは予行演習、今度は実力が試されると感じます。
KDDI、IIJに1割出資 NTTが保有株を一部売却 – 日本経済新聞
KDDIは2023年5月18日、株式会社インターネットイニシアティブ (本社: 東京都千代田区、代表取締役社長: 勝 栄二郎、以下 IIJ) と両社の有する事業資産を生かした相互の企業価値向上に向け資本業務提携契約を締結しました (以下 本資本業務提携)。
KDDIは、IIJの発行済株式総数の10.0%に当たる普通株式18,707,000株を総額512億円 (1株当たり2,739円) で日本電信電話株式会社から買い付けする予定です。■背景
KDDIは2022年5月にKDDI VISION 2030と中期経営戦略を発表し、「DX」を事業の柱に、法人企業やその先にいるお客さまの課題解決・社会貢献を推進しています。IIJは1992年12月に日本初の国内インターネット接続事業者として創業し、セキュリティ、クラウドなどの領域で多様なネットワークサービスを自社開発のうえ、システムインテグレーションとあわせて複合提供するなど高い技術力を有しています。KDDIは本資本業務提携を通じて、「DX」におけるモバイルや固定電話などの「コア事業」と、クラウドやIoTサービスなどの「NEXTコア事業」の拡大を目指していきます。
■業務提携の内容
IIJとKDDIは以下に定める業務および事業に関して提携を行い、相互に協力することを合意しました。
KDDI インターネットイニシアティブと資本業務提携契約を締結
- IIJによるKDDIの通信サービスなどの最適な調達
- IIJとKDDIのそれぞれの子会社を含む事業領域での各種協業の検討
- IIJとKDDIの法人分野およびモバイルサービス領域での商材の相互活用および共同開発などの検討
- 人材の交流
Google、Colabに無料のAIコーディング機能の追加を発表
Googleは、Colabに無料でコード補完、自然言語によるコード生成、さらにはコード支援チャットボットなどのAIコーディング機能を近々追加することを発表しました。
Colabは、PaLM 2をベースに構築されたコードモデルのファミリーであるCodeyを使用しており、Codeyは、高品質なコードの大規模データセットで微調整され、さらにPythonとColabに特化してカスタマイズされています。

OpenAI、2019年以来となる言語モデルを公開する準備
The Informationの報道によれば、OpenAIは、2019年以来となる言語モデルを公開する準備を進めている模様、但しGPTと競合するようなモデルをリリースすることは無いとのこと。Meta社が2月に公開したLLaMAが洗練されていることから圧力を掛ける狙い。
なお、LLaMAの特徴は、GPT-3よりも圧倒的に少ないパラメーター数でGPT-3と同等またはそれ以上の性能を示しています。例えば、LLaMA-13Bは、GPT-3 (175B)よりも13倍少ないパラメーター数で、BoolQやPIQAなどのベンチマークでGPT-3を上回る結果を出しています。また、LLaMAは、単体GPUでも問題なく動作することが報告されており、コンシューマーレベルのハードウェア環境でも利用できる可能性があります。
LLaMA: Open and Efficient Foundation Language Models
OpenAIのSam Altman、上院公聴会でAI規制を強く求める
「もしこのテクノロジーが間違った方向に進んでしまったら、非常に悪い結果を招く可能性があると思います。」
「そのようなことが起きないように、政府と協力していきたい。」
アルトマン氏は、マーカス博士が提案したアイデアに倣い、大規模なAIモデルの開発ライセンス、安全規制、AIモデルが一般に公開される前に通過すべきテストを実施する機関の設立を提案しました。この技術が一部の雇用を破壊するが、同時に新しい雇用を生み出すとし、”政府の重要検討事項 “だと述べました。
regulation should take effect above a capability threshold.
— Sam Altman (@sama) May 18, 2023
AGI safety is really important, and frontier models should be regulated.
regulatory capture is bad, and we shouldn't mess with models below the threshold. open source models and small startups are obviously important. https://t.co/qdWHHFjX4s
AIのガバナンスについて
高度なAIのためのIAEA:国際原子力機関のようなものは、考える価値があり、技術の特性上、実現可能かもしれない。 (そして、これをわざと誤解されることを避けるために、このような規制はAI能力を枠に閉じ込めないことが重要である)
Sam Altman

Governance of superintelligence
Now is a good time to start thinking about the governance of superintelligence—future AI systems dramatically more capable than even AGI.
確率的オウム🦜のつぶやき。
テキサスA&M大学の教授がChatGPTを使用して、論文を書くためにソフトウェアを使用したかどうかをチェックしたところ、ChatGPTが約半数の論文を書いたと主張し、落第させた模様。
なお、ChatGPTのような自然言語処理では、「幻覚」(hallucination) と呼ばれる生成された内容もあり、AIによって作成されたコンテンツ (独自のものを含む) を識別するように設計されていません。
A Texas professor failed more than half of his class after ChatGPT falsely claimed it wrote their papers
ChatGPTの6つのリスクを特定-Gartner
Gartnerによると、法務およびコンプライアンスの責任者が評価すべきChatGPT の 6 つのリスクを特定しました。
リスク 1 – 捏造された不正確な回答
ChatGPTや他のLLMツールで最もよく見られる問題は、表面的にはもっともらしいが、不正確な情報を提供する傾向があることだろう。
Friedmannは「ChatGPTは、間違った答えを捏造したり、存在しない法律や科学の引用を含む “幻覚:hallucinations”を見る傾向があります」そして、「法務・コンプライアンス担当者は、ChatGPTで生成された出力が正確かどうか、適切かどうか、実際に役に立つかどうかを、受け入れる前に確認することを従業員に義務付けるガイダンスを発行すべきです」と述べています。
リスク 2 – データのプライバシーと機密保持
法務・コンプライアンス担当者は、チャット履歴が無効化されていない場合、ChatGPTに入力された情報は、トレーニングデータセットの一部となる可能性があることを認識する必要があります。
Friedmannは「プロンプトで使用された機微な情報、私的な情報、または機密情報は、社外のユーザーの回答に組み込まれる可能性があります」そして、「法務とコンプライアンスは、ChatGPTの使用に関するコンプライアンスの枠組みを確立し、機密性の高い組織や個人のデータを公共のLLMツールに入力することを明確に禁止する必要があります。」と述べています。
リスク 3 – モデルと出力のバイアス
OpenAIによるChatGPTにおける偏見や差別を最小限に抑えるための努力にもかかわらず、これらの問題はすでに発生しており、継続的なリスクに備える必要があります。
Friedmannは「バイアスを完全に排除することは不可能だと思われますが、法務とコンプライアンスは、AIのバイアスに関する法律を常に把握し、ガイダンスが準拠していることを確認する必要があります」そして、「これには、アウトプットが信頼できることを確認するために専門家と協力し、データの品質管理を設定するために監査や技術部門と協力することが必要かもしれません。」と述べています。
リスク 4 – 知的財産 (IP) および著作権のリスク
特にChatGPTは、著作物を含む可能性の高い大量のインターネットデータで訓練されています。そのため、その出力は著作権や知的財産権の保護に違反する可能性があります。
Friedmannは、「ChatGPTは、その出力がどのように生成されるかについて、ソースの参照や説明を提供していません」そして、「法務・コンプライアンス担当者は、ChatGPTの出力に適用される著作権法の変更に注意し、ユーザーが生成した出力が著作権や知的財産権を侵害しないよう精査するよう求める必要があります」と述べています。
リスク 5 – サイバー詐欺のリスク
悪質な業者はすでにChatGPTを悪用して、偽の情報を大規模に生成しています(例:偽のレビューなど)。さらに、ChatGPTを含むLLMモデルを使用するアプリケーションは、悪意のある敵対的なプロンプトを使用して、マルウェアコードの記述や有名なサイトに似せたフィッシングサイトの開発など、モデルが意図しないタスクを実行させるハッキング手法であるプロンプトインジェクションにも影響を受けやすくなっています。
Friedmannは「法務・コンプライアンス担当者は、この問題について企業のサイバーセキュリティ担当者にメッセージを出すかどうかを検討するために、サイバーリスクのオーナーと連携する必要があります」そして、「また、デューデリジェンスの情報源の監査を行い、その情報の質を確認する必要があります。」と述べています。
リスク 6 – 消費者保護のリスク
ChatGPTの利用状況を消費者に開示しない企業(例えば、カスタマーサポートのチャットボットなど)は、顧客の信頼を失い、様々な法律の下で不公正な行為として告発されるリスクを抱えています。例えば、カリフォルニア州のチャットボット法では、特定の消費者とのやり取りにおいて、企業は消費者がボットとやり取りしていることを明確かつ目立つように開示しなければならないと定めています。
「法務・コンプライアンス担当者は、組織のChatGPT利用がすべての関連規制や法律に準拠し、顧客に対して適切な開示がなされていることを確認する必要があります」とFriedmannは述べています。
CTIVD Automated OSINT(自動化されたOSINT): オープンソース調査のためのツールおよびソースについて
CTIVDによる総合情報保安局(AIVD)と軍事情報保安局(MIVD)の自動化されたOSINTの調査レポートです。