Draft NISTIR 8332
Trust and Artificial Intelligence
Brian Stanton
Theodore Jensen
概要
自動運転車、スマート ビルディング、自動健康診断、セキュリティ監視の改善などの進歩が期待される人工知能 (AI) 革命が到来しています。実際、多くの人々は、音声コマンドを使用してインターネットを検索したり、電話をかけたり、リマインダー リストを作成する「パーソナル」アシスタントとして AI を生活に取り入れています。それらのシステムが AI であることを消費者が知っているかどうかは不明であるものの、これらのシステムへ依存することは、ある程度信頼できると見なされることを意味します。現在、AIシステムの信頼性を評価するために、「正確性」「信頼性」「説明可能性」など、システムの特性を測定する取り組みが多く行われています。これらの特性は必要ですが、AIシステムがシステム要件を満たしているから信頼できると判断しても、AIの普及は望めません。最終的にシステムに信頼するのは、AIの影響を受けるユーザーである人間なのです。
自動化されたシステムに対する信頼の研究は、以前から心理学の研究テーマとして取り上げられてきました。しかし、人工知能システムは、ユーザーの信頼に固有の課題をもたらします。AIシステムは、膨大な量のデータのパターンを使って動作します。もはや、人間の仕事を自動化するのではなく、人間ができない仕事を自動化するのです。さらに、AIはその一連の信念を動的に更新する(すなわち「学習」する)ように構築されており、そのプロセスは設計者でも容易に理解することができません。このような複雑さと予測不可能性から、AIのユーザーはAIを信頼する必要があり、ユーザーとシステムの関係はダイナミックに変化しています。
信頼できるシステムの構築に向けた研究と並行して、AIに対するユーザーの信頼を理解することで、以下のことが可能になります。この新しい技術の利点を活かし、リスクを最小化するために、必要なものです。
キーワード
人工知能; 自動化(オートメーション); 認知; 共同作業(コラボレーション); 知覚; システムの特徴; 信頼(トラスト); 信頼性; ユーザー; ユーザー体験(ユーザーエクスペリエンス)、
目次
1. はじめに
2. 信頼は人間の特性
2.1.信頼の目的
2.2.不信と認識
2.3.信頼、不信、協力: それらが果たす役割
2.3.1.信頼と不信につながる要因
3. 自動化への信頼
3.1.社会的アクターとしてのコンピュータ
3.2.人的要因、信頼、自動化
4 人工知能への信頼
4.1. AIの信頼性
4.2. AI に対するユーザーの信頼
4.3.ユーザーの信頼の可能性
4.4.認知されたシステムの信頼性
4.4.1.ユーザー体験
4.4.2.認識される技術的信頼性
4.5. AI とユーザーの信頼の例
4.5.1. AI医療診断
4.5.2. AI選曲シナリオ
5 まとめ
6 引用された著作物
付録 A
前書き
自動化システムにおけるユーザーの信頼の研究は、以前は心理学の研究のトピックでしたが、人工知能(AI)は、以前のユーザーインターフェイスのパラダイムを劇的に変えます。 AIシステムは、人間の脳が理解できない大量のデータのパターンに「気付く」ようにトレーニングできます。自動化にタスクの実行を要求するのではなく、実行できないタスクの実行を自動化に要求しています。 AIに2つの異なるタイミングに同じタスクを実行するように要求すると、AIが2つの要求の間の時間に「学習」したため、2つの異なる回答が得られる可能性があります。 AIには、AIシステムを構築する人でさえ常に予測できるとは限らない方法で、独自のプログラミングを変更する機能があります。このかなりの程度の予測不可能性を考えると、AIユーザーは最終的にAIを信頼するかどうかを決定する必要があります。 AIユーザーとAIシステムの間のダイナミクスな関係であり、ユーザーの信頼が不可欠な部分であるパートナーシップです。 AIで期待される生産性と生活の質の向上を実現するには、ユーザーの信頼を理解することが重要です。まず、私たち自身の進化の歴史における信頼の不可欠な役割を確立することによって、AIシステムの開発におけるユーザーの信頼の重要性と、これが現在の認知プロセスをどのように形作ったかについて概説します。次に、人間間の信頼の要因に関する研究について簡単に説明し、自動システムのオペレーターに信頼の概念を拡張した研究の実質的な本体を要約します。
次に、AIに関連する固有の信頼の課題に具体的に対処します。 AIの技術的な信頼性とユーザーの信頼の概念を区別します。次に、AIシステムに対するユーザーの信頼レベルを表す例示的な方程式を提案します。これには、運用コンテキストに関する技術的な信頼性特性の判断が含まれます。このドキュメントは、ユーザーがAIシステムをどのように信頼しているかを理解するための将来の研究の重要な領域を強調することも目的としています。将来の研究のこれらの領域は、セクション内のテーブルに配置されます。
信頼は人間の特性です
2.1.信頼の目的
信頼は、複雑さを軽減するためのメカニズムとして機能します[1]。私たちが信頼することを決定するとき、私たちは潜在的な結果の数を制限することによって、相互作用パートナーの将来の行動の固有の不確実性を管理しています。不信は同じ目的を果たします。Kaya[2]が述べているように、
先祖代々の環境では、人間が最も致命的な敵である他の人間に対して用心深くなることを考えると、不信感が生き残るための鍵でした。他の人間が潜在的に危険で搾取的であると考えた個人は、生き続けて自分の遺伝子を将来の世代に引き継ぐ可能性が高かったのです。
信頼の発展は、個人が生き残るための唯一の責任を負うことを軽減します。 信頼は、協調的な利点を利用することを可能にします。 Taylor [3] は、著書「The Tending Instinct」で次のように述べています。
日々の生存の必要性の主張が沈静化するにつれて、集団生活のより深い重要性が明確になってきました。 狩猟と戦争の共同作業は、社会集団が達成できることの中で最も小さなものです。
全体として、進化の状況では、信頼と不信は、社会的相互作用の利益とリスクを管理するために使用されます。別の個人に依存することには利点がありますが、同時に、搾取や欺瞞に対して脆弱になります。信頼が少なすぎると、欲しくなるでしょう。信頼しすぎると、あなたは利用されます。ゲーム理論の研究により、信頼できるものと信頼できないものを区別するための戦略である条件付き信頼が進化的に有利であることが確認されています[4] [5] [6]。このように、信頼は私たちの生存の基本であり、私たちの相互作用を推進し続けています。
2.2.不信と認知
私たちの思考における信頼と不信の役割は、私たちの進化論的闘争におけるそれらの中心的な位置と一致しています。特に、人間の認知は主に合同性によって特徴付けられます。私たちは、以前の指示対象と一致する方法で受信情報を処理する傾向があります。これは、カーネマンの著書「Thinking Fast and Slow」で、確証バイアス[7]として説明されています。同様に、アクセシビリティ効果は、後続の処理を変更する初期刺激への曝露によって特徴付けられます。正の素数(最初の指示対象)は、負の素数よりも無関係なターゲットの一致してより肯定的な評価を呼び出します[8]。しかし、不信感は合同処理のそのような影響を減らすことがわかっています。代わりに、不信感は、不一致の代替案の検討を呼び起こすように思われます[8]。
たとえば、これはWason Rule Discovery Taskで実証されており、参加者は番号シーケンス「2、4、6」が表示された後、次の2つの手順を完了します。1)番号シーケンスを特徴付ける仮説ルールを生成し、2)いくつかを生成します。仮定されたルールをテストするための数列。一般に、ほとんどの個人はルール「+2」を仮定し、2番目のステップ(陽性仮説検定)のルールに従うシーケンスのみを生成します。これは、合同な処理への傾向を強調しています。この場合、多くの場合、真のルール(つまり、「一連の増加する数」)の発見に失敗します。実験によると、気質の信頼度が低い個人や不信感を持ってプライミングされた個人は、ルールに従わないシーケンスを生成する可能性が大幅に高いことがわかりました(否定的な仮説検定)[9]。不信感は、代替案の検討を呼びかけることにより、タスクのパフォーマンスを改善しました。同様に、不信の状態は、不一致の概念へのより迅速な対応と、より多くの不一致の自由連想法につながることがわかっています[10]。
私たちの合同な処理を混乱させることへの不信のこの影響は、私たち自身を欺瞞から守るその機能を考えると理解できます。 Mayo [8]は、これを適切に要約しています。
…物事が見た目どおりではない可能性がある場合、精神システムの活性化のパターンには不一致が含まれます。つまり、信頼できない環境の影響を受けないように、与えられた刺激の代替案を自発的に検討し、非類似性を探します。
不信のこの認知的考察で再び強調されるのは、リスクの役割です。不信感は、他のアクターの行動に対する脆弱性をより顕著にします。これは、信頼が特定の状況におけるリスクの認識に不可避的に関連していることを私たちに思い出させます。ゲーム理論に続いて、条件付きの信頼と不信は、協力の潜在的な利益を享受しながら、個人を欺く他者から保護します。仲間に依存するという私たちの日常の意欲を駆り立てる認知メカニズムは、最終的には進化的適応の環境で裏付けられました[11] [12]。言い換えれば、私たちの進化の歴史は、今日の信頼をもってリスクと不確実性をどのように管理しているかを示しています。
2.3.信頼、不信、協力:それらが果たす役割
信頼と不信は非常に基本的なものであるため、日常生活の中で最もありふれた決定の中に隠されていることがよくあります。ある程度の信頼がなければ、他人への圧倒的な恐れのために家を出ることはありません。一方、不信感は、私たちが潜在的に欺瞞的な行為者と誤った情報の世界をナビゲートすることを可能にします。
Luhmann[13]が指摘したように、信頼と不信は反対ではなく、機能的に同等です。私たちは両方を使用して、将来の不確実性を現在と調和させます。誰かが信頼されないことだけを決定しても複雑さは軽減されませんが、信頼できない理由を考慮すると、複雑さが軽減されます[13]。 Lewicki、McAllister、およびBies [14]は、多くの組織的関係、そして多くの場合最も健全な関係は、同時に高いレベルの信頼と不信(たとえば、「信頼するが検証する」)によって特徴付けられると提案しました。私たちは常に信頼と不信の両方を使用して、他者とのやり取りにおけるリスクを管理し、好ましい結果を達成します。
Gambetta[15]は、現代の信頼環境が、個人間の信頼と、私たちの行動を支配する規則や規制との間の相互作用でどのように構成されているかを示しています。
強制力のある契約で起こりうるすべての不測の事態をマッピングする無制限の計算能力に恵まれていれば、信頼は問題になりません。
Gambettaは、そのような契約または合意を「信頼の経済化」と呼び、これらは信頼に十分に取って代わるものではなく、個人が信頼について心配する程度を減らすのに役立つことに注意します。
これは、必ずしもその当事者に「信頼」を構築することなく、当事者が何かを行うことを「信頼する」ことを強制する法規制に関するHillとO’Hara’sの[11]議論に反映されています。受託者は、規則が整備されていないと受託者が有利に行動しないと推測する可能性があるため、このような規制は不信につながる可能性さえあります。これは、私たちの種が信頼が進化した条件から大部分が取り除かれ、規制メカニズムを介して信頼をなくすことに主に焦点を当てている社会に住んでいるにもかかわらず、信頼は私たちの相互作用の基本であり続けることを強調します。その「複雑さを軽減する」機能[1]は依然として重要です。その結果、多くの研究者は、ある人の別の人への信頼を知らせる特徴を特定しました。
2.3.1.信頼と不信につながる要因
Mayer、Davis、およびSchoormanの組織的関係における信頼のモデル[16]は、受託者に対する受託者の「脆弱になる意欲」に寄与する要因についての倹約的な見方を示しています。それは間違いなく、最も広く参照されている信頼に関する研究です。モデルには、受託者関連、受託者関連、および文脈上の要因が含まれます。これらの各要素は、AIユーザーの信頼に関する後の説明で検討されます。
信頼者の中心的な要素は気質の信頼であり、信頼者の一般的な意欲または他の人々に依存する傾向として定義されます[17]。これは、相互作用全体で安定した特性と見なされます。 AIユーザーの信頼については、AIを信頼する各ユーザーの固有の素因を説明するために、ユーザー信頼の可能性(UTP)を定義します。 2人のユーザーがシステムを同等に信頼できると認識する場合がありますが、UTPは、認識された信頼性が全体的な信頼に与える影響の違いを説明しています。
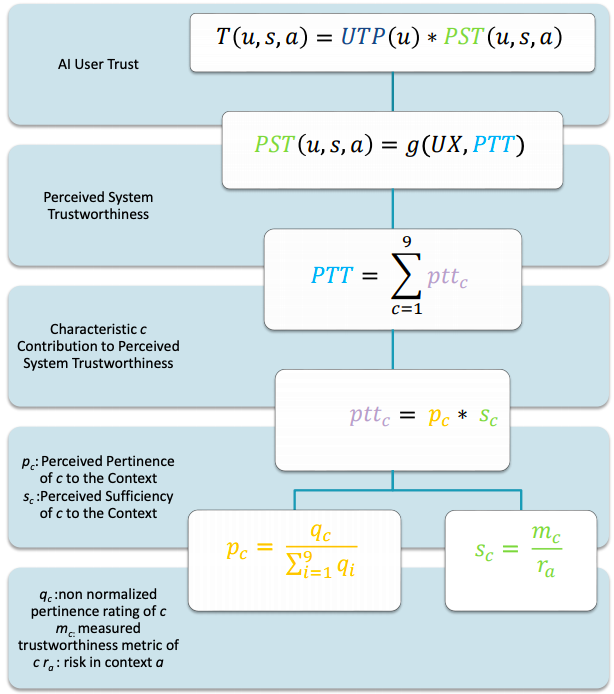
受託者の要素は、その能力、慈悲、誠実さ、より具体的には、これらの特性に対する受託者の認識で構成されます。能力は、受託者が所有するドメインまたはコンテキスト固有のスキルのセットです。慈悲とは、受託者が受託者に対して抱く善意の感覚です。誠実さには、受託者が遵守する一連の容認できる原則の維持が含まれます。 Mayer et al[16]の認識された信頼性の特性は、他のいくつかの研究者による構成の定式化で提案された特性を反映しています。たとえば、Rempel、Holmes、およびZanna [18]は、ロマンチックなパートナー間の信頼に焦点を当て、信頼の構成要素として予測可能性、信頼性、および信仰を特定します。Becker[19]は、受託者の信憑性、信頼性、およびセキュリティについて言及しています。いずれの場合も、受託者の(認識された)スキル、性格、および意図は、当然のことながら、受託者の脆弱性に対する意欲に関連しています。 AIユーザーの信頼については、知覚システムの信頼性(PST)を、信頼に関連するAIシステムの特性に対するユーザーのコンテキスト認識として定義します。これから説明するように、これには、システムのさまざまな技術的特性とユーザー体験の要因の認識が含まれます。
重要なのは、人間と人間の信頼の場合と同様に、信頼性は受託者の特性を直接反映するのではなく、信頼者によって認識されるということです。
状況要因は、受託者または受託者の特性とは無関係です。前述の特性と同様に、信頼に関連する状況要因は、信頼者がさらされている脆弱性の程度に関連しています。これらには、協力を強要したり、「信頼を経済化する」ことを目的としたメカニズムや規則が含まれる場合があります[15]。重要なことに、Mayer etal [16]の信頼と認識されたリスクを区別します。後者は、「特定の受託者との関係を含む考慮事項以外」の否定的および肯定的な結果の評価で構成されています。彼らは、信頼者の信頼のレベルが彼らの認識されたリスクのレベルを超える場合、「関係におけるリスクテイク」または信頼行動が生じることを示唆しています。信頼は本質的にリスクに関連していますが、それらは別個の構成要素です。 AIユーザーの信頼における状況要因を説明するために、PSTは、AIシステムが実行している特定の展開コンテキストまたはアクションに関して評価されます。 2つの異なるタスクまたはリスクのレベルは、信頼性の2つの異なる認識につながります。
テクノロジーとの相互作用の脆弱性は、同様の信頼ベースの相互作用の条件を作成します。人間とテクノロジーの相互作用の問題は次のようになります。進化的に根付いた社会的に条件付けられた信頼メカニズムは、機械にどのように反応するのでしょうか。
自動化への信頼
3.1.社会的アクターとしてのコンピューター
Computers as Social Actors(CASA)パラダイムは、構成概念としての人間とマシンの信頼の実行可能性をサポートします。 CASAは、コミュニケーション研究者によって、人間がコンピューターに社会的に反応することを実証するために使用されてきました[20]。 CASAの実験では、調査中の社会現象で人間の1人をコンピューターに置き換えて、人間による社会的反応が成り立つかどうかを確認します[21]。この方法は、人々が礼儀正しさ[21]、性別のステレオタイプ[22]、および相互開示の原則[23]を使用することを明らかにしました。361台のコンピューター。特に、元のCASA実験は、経験豊富なコンピューターユーザーがシンプルなテキストベースのインターフェイスを操作して実施されました[24]。
CASAは、機械との相互作用の独自の学習面を除外していませんが、人々との相互作用に対する私たちの素因を強調しています。信頼と不信は、人間の仲間の不確実な行動を予測するために開発されました。私たちの信頼の使用が自動化にまで及ぶのは当然です。
3.2.ヒューマンファクター、信頼と自動化
ヒューマンファクターの研究者は、作業システムの自動化の普及に対応して信頼の研究を開始しました。 Muir [25]は、自動化に対する行動はその技術的特性のみに基づいているという概念に最初に異議を唱えた人の1人でした。彼女の見解は、人々の間の信頼についての前述の議論のテーマを思い起こさせます。オペレーターは、自動化されたシステムについて完全な知識を持つことはできません。受託者(自動化)の行動の自由、および受託者の行動のすべての可能性を説明することができないため、受託者(オペレーター)の認識が重要になります。
Muirの[25]は、現金自動預け払い機を使用している人と使用していない人の例を示しています。銀行機の特性は一定のままであり、テクノロジーに対するユーザーの信頼をもたらしています。
この格差の原因は、個人自身、つまり彼らが状況にもたらす何かにあるに違いありません。
その後の実験により、オペレーターは自動化システムに対する主観的な信頼レベルについて報告できること、この信頼はシステムのプロパティによって適切な方法で影響を受け、信頼は自動化(の使用)への依存と相関していることが確認されました[26] [27 ]。
この初期の研究以来、研究者は技術への信頼に関連する要因のかなりの量の理解に貢献してきました。 Lee and Seeの[28]レビューは、自動化システムの複雑さが増すにつれて、信頼の理解がどのように必要になるかを強調しています。 Hoff and Bashir [27]は、Lee and See’s [28]に続く実証研究をレビューし、自動化への信頼における変動の3つの原因、つまり、処分、状況、および学習を定義しました。処分要因には、他の特性の中でもとりわけ、信頼者(つまり、自動化オペレーターまたはユーザー)の年齢、文化、および性格が含まれます。
状況要因は、人間と自動化の相互作用のコンテキストと、ワークロードやリスクなどのタスクのさまざまな側面に関係します。学習した信頼は、システムのパフォーマンス特性と、パフォーマンスの解釈方法を彩る設計機能の結果です。この3層モデルは、Mayer et al[16]の人間-人間モデルと互換性があります。このモデルは、信頼者の特性(気質)、認識されたリスク(状況)、および信頼された行動を観察することによって動的に更新される認識された信頼性を考慮します(学習済み) 。 Mayer et alのモデルに関して以前に説明したように、これらの人間と自動化の信頼係数は、AIユーザーの信頼に関する後の説明に役立ちます。
実行可能な構成要素として人間と機械の信頼が確立されたとしても、それが人間と人間の信頼にどのように関連するかという問題は残っています。実際、前述の人間と自動化の信頼の研究者は、信頼に関する社会学的および心理学的理論から引き出して、独自の理論を策定しました[25] [28]。 CASAはこの理論的拡張をサポートしています[20]。しかし、他の人との相互作用のために進化した私たちの信頼メカニズムは、マシンとの相互作用にどの程度関連していますか?自動化されたシステムを信頼するとき、私たちは何か違うことをしますか?
Madhavan と Wiegmann [29]は、自動化されたエイズと人間のエイズの認識を比較するいくつかの研究をレビューしました。彼らは、機械が不変であり、人間が柔軟であるという認識が、これら2つの異なる種類に対する信頼の根本的な違いにつながることを示唆しています。エイズの。たとえば、完璧な自動化スキーマは、自動化が完璧に実行されることを人々が期待していると考えています。その結果、自動化によって発生したエラーは、自動化されたエイズによって発生したエラーよりも信頼に悪影響を及ぼします。より擬人化された(つまり、人間のような)自動化がより大きな「信頼の回復力」を引き出すことを発見した研究は、より人間らしい技術がより容易に許されるというこの概念を支持しています[30]。自動化に関連する機械の不変性の認識が、AIの出現によってどの程度持続するのか疑問に思う必要があります。
人工知能への信頼
繰り返しになりますが、Luhmann’sの[1]社会学的視点は、不確実性に直面した場合の信頼の役割を強調しています。
したがって、文明の科学的および技術的発展がイベントを制御し、社会的メカニズムとしての信頼を物事の支配に置き換え、それを不要にすることは期待されていません。代わりに、テクノロジーが生み出す未来の複雑さに耐える手段として、信頼がますます求められることを期待する必要があります。
技術的な受託者については特に言及していませんが、ルーマンは、複雑さと不確実性に基づいて、AIユーザーの信頼に関連する特定の課題の舞台を設定します。
4.1.AIの信頼性
コンピューティングに適用される信頼できるものの使用は、ビル・ゲイツが2002年にすべてのマイクロソフト従業員に送信した電子メールにまでさかのぼることができます[31]。このメールで彼は次のように述べています。
…信頼できるコンピューティング。これが意味するのは、顧客は常にこれらのシステムが利用可能であり、情報を保護することに依存できるということです。信頼できるコンピューティングとは、利用可能で、信頼性が高く、安全なコンピューティングです…[32] [33] [34]
この信頼できるコンピューティングの実践は、コンピュータサイエンスやシステムエンジニアリングの分野で引き続き採用されています。それらは: 米国電気電子技術者協会(IEEE)および国際電気標準会議(IEC)/国際標準化機構(ISO)/ IEEE標準の信頼性の定義は、概念とゲイツのシステムの信頼性属性に基づいて構築されています。
(1)コンピュータシステムが提供するサービスに正当に信頼を置くことができるようなコンピュータシステムの信頼性[33]
(2)アイテムの、必要に応じて実行する能力[34](追加の強調)。
AIが信頼できるために必要な特性の作成を促進するのは、この2番目の定義です。特定のAIユースケースに基づいた特性の開発、それらの測定方法、および測定のあり方はすべて、AIシステムの開発にとって重要です。ただし、特性定義プロセスは優れていますが、ユーザーがAIを信頼することを保証するものではありません。前述のように、信頼者の処分要因も信頼に影響を与えるため[27]、すべてのユーザーがAIシステムを同じように信頼するわけではありません。AIシステムが「信頼に値する」と主張しても、自動的に信頼されるとは限りません。
4.2. AIに対するユーザーの信頼
他の人や自動化に対する私たちの信頼が信頼性の認識に基づいているのと同じように、AIに対するユーザーの信頼はその信頼性の認識に基づいています。 AIシステムの実際の信頼性は、ユーザーが認識している限り影響力があります。信頼は、技術的な信頼性の特性に対するユーザーの認識の関数です。
ユーザーuがコンテキストa内でAIシステムsと対話するシナリオを考えると、システムに対するユーザーの信頼はT(u、s、a)として表すことができます。
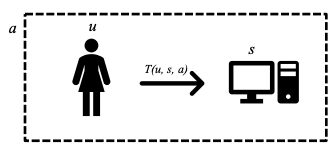
図1AIユーザーの信頼シナリオ
人間と人間と人間の自動化の信頼に関する研究は、AIシステムにおける信頼の変動の2つの主な原因、つまりユーザーとシステムを示唆しています。 したがって、AIに対するユーザーの信頼を、ユーザーの信頼の可能性UTP(u)と知覚されるシステムの信頼性PST(u、s、a)の2つの主要なコンポーネントの観点から概念化します。 ユーザーの信頼は、次の2つのコンポーネントの関数fとして表すことができます。
T(u, s, a) = f(UTP(u), P(u, s, a))
UTPとPSTの関係の性質についての調査が必要です。このドキュメントでは、説明のために、2つのコンポーネントが独立しており、全体的な信頼に向けて増加していると見なします。さらに、2つの積が[0、1]の範囲にあるように、それぞれを確率値と見なします。これは、ユーザーuがシステムsを信頼して指定されたアクションを実行する可能性を表します。
T(u, s, a) = UTP(u) * P(u, s, a)
残りの議論と例を通して、この例示的な確率論的仮定を実行しますが、知覚された信頼性と信頼の文脈的性質を強調します。信頼は、受託者(システム)の期待される行動に基づいており、文字通り「チャンス」の決定として解釈されるべきではありません。確率論的表現により、さまざまな要因による信頼の違いを定量的に表現することができます2。
4.3.ユーザーの信頼の可能性
ユーザー信頼の可能性と呼ばれるUTP(u)は、AIシステムへの信頼に影響を与えるユーザーuの固有の個人属性で構成されます。 ユーザーの特性は、テクノロジーへの信頼に影響を与えるものとして示唆されています[35] [27]。 これらには、性格、文化的信念、年齢、性別、他のAIシステムの経験、技術的能力などの属性が含まれます。 AIシステムを信頼するこれらのユーザー変数やその他のユーザー変数の役割を確立するには、さらに調査が必要です。
表1ユーザーの信頼に関する潜在的な調査の質問
| 調査の質問 |
| 1.ユーザーの信頼の可能性を定義する属性のセットは何ですか? |
4.4.知覚されるシステムの信頼性
知覚システムの信頼性と呼ばれるPST(u、s、a)は、ユーザー体験(UX)とAIシステムの知覚技術信頼性(PTT)の関係で構成されています。これらの2つのコンポーネントは、コンテキスト内のAIシステムに対するユーザーの信頼におけるフロントエンド関連(UX)およびバックエンド関連(PTT)の要因と考えることができます。

図2ユーザー体験のフロントエンドとAIシステムの信頼できる特性のバックエンド
PST(u, s, a) = g(UX, PTT)
説明のために、これは独立した確率の乗法関数と考えることができます。
知覚されるAIシステムの信頼性
PST(u, s, a) = UX * PTT
したがって、全体的な信頼TTと同様に、PSTは[0、1]の範囲にあり、システムが信頼できると認識される程度を表します。 UXとPTTの関係を特定するには、さらなる研究が必要です。
4.4.1.ユーザー体験
ユーザー体験は、構成する技術的な信頼性の特性の外部にあるユーザー体験の設計要素から、知覚されるシステムの信頼性への貢献を表します。
PTTこれらの外部要因は、ユーザーの認識にも関連しています。
ユーザー体験の主要コンポーネントであるユーザビリティは、国際標準[20]に準拠した、効率、有効性、ユーザー満足度の3つの指標で構成されています。これらのメトリックは、さまざまな方法で測定できます。効率は、タスク完了率(すべてのタスクを完了するのにかかった時間)とタスク時間(単一のタスクに費やされた時間)の両方になります。有効性は、発生したエラーの数またはタスク出力の品質であり、ユーザー満足度は、欲求不満の量、関与の量、または楽しみの量である可能性があります。
ユーザビリティの測定方法にはさまざまなバリエーションがあるため、AIシステムの信頼性を認識するために、1つのユーザビリティスコアが使用されます。ユーザビリティ指標を1つのスコアに組み合わせるにはさまざまな方法があります[21] [23] [22]。最もよく知られている方法は「単一のユーザビリティメトリック」(SUM)[22]です。このメソッドは、入力タスク時間、エラー、満足度、およびタスク完了を受け取り、信頼区間を使用してSUMスコアを計算します。
UX変数の課題は、システムの信頼に最も影響を与えるユーザビリティ手法を見つけることです。
表2ユーザー体験調査の質問
| 調査の質問 |
| 1.どのユーザー体験メトリックがユーザーの信頼に影響を与えますか? |
| 2.ユーザー体験の指標はユーザーの信頼にどのように影響しますか? |
4.4.2.知覚される技術的信頼性
AIシステムの設計者とエンジニアは、システムの信頼性に必要ないくつかの技術的特性を特定しました。この記事の執筆時点では、AIシステムの信頼性を定義する、精度、信頼性、回復力、客観性、セキュリティ、説明性、安全性、説明責任、プライバシーの9つの特徴があります(プライバシーは[36]の後に追加されています)。エンジニアリングの観点から、AIシステムが信頼されるためには、これらの特性が必要です。
ユーザーの信頼の観点からは、これらの特性は必要ですが、信頼には十分ではありません。最終的に、利用可能な技術情報に対するユーザーの認識が、ユーザーの信頼に貢献します。知覚される技術的信頼性は、次の式で表すことができます。ここで、cは9つの特性の1つであり、pttcはユーザーによる特性cの判断です。
式1知覚されるシステムの技術的信頼性
$$PTT=\sum_{c=1}^{9}ptt_c$$
変数pttcは、PTT全体に対する各特性の寄与を示し、コンテキストpcに対するその関連性と、コンテキストscに対するその特性の測定値の十分性で構成されます。
式2信頼できる特性の認識された適切性と認識された十分性の関係
$$ptt_c=p_c*s_c$$
この定式化は、人間の意思決定を定量的に表すために使用される効用関数を彷彿とさせます。その中での意思決定結果の効用は、その結果の確率とその価値の積です。結果の有用性が高いのは、確率が高いか、価値が高いか、またはその両方が原因である可能性があります。考えられるすべての結果の効用の合計は、期待される「見返り」を表します。
認識された技術的信頼性は、各特性の認識された十分性の合計であり、その関連性によって重み付けされています。ここで、特性の高い「効用」は、高い関連性、高い十分性、またはその両方が原因で発生する可能性があります。必ずしも「ペイオフ」と同じではありませんが、これらのユーティリティの合計は、各特性からの寄与に基づいて、システムの認識された信頼性の程度を表します。以下では、2つのコンポーネントについて詳しく説明します。
4.4.2.1.関連性
適切性は「この特性はこのコンテキストにとってどの程度重要ですか?」という質問に対する答えです。
適切性には、ユースケースの固有の性質に基づいて、どの技術的信頼性特性が最も重要であるかをユーザーが検討することが含まれます。
ヒューマンオートメーションの信頼の彼女のモデルで、Muir[25]は、知覚された信頼性のさまざまな要素(永続性、技術的能力、作業遂行責任)の相対的な重要性は等しくなく、コンテキスト間で同じではないと提案しました。同様に、Mayer、Davis、およびSchoorman [16]は、コンテキストが、信頼に対する認識された信頼性特性(能力、整合性、および慈悲)のそれぞれの相対的な重要性にどのように影響するかを示しています。したがって、適切性は、全体的な認識された信頼性に対する各特性の貢献の「重み」です。
1つの特性のみが文脈上重要であると認識された場合、その認識された関連性は1になります。2つの特性のみが重要であると認識された場合、同様に、それぞれの認識された関連性は0.5になります。関連する特性が他の特性と関連性を共有する場合、信頼にとって関連する特性がそれほど重要ではないことを意味するものではありません。 2つの特性が両方ともコンテキストパフォーマンスにとって重要であると見なされる場合、それらはPTTに等しく貢献します。
関連性は、他の特性と比較したccの重要性の知覚的重み付けです。したがって、すべてのpc値の合計は1になり、それぞれが全体的な信頼性評価に対する重要度のパーセンテージを表します。各特性の測定された関連性qcが合計が1でないスケールで評価された場合、この正規化された知覚関連性pcは、qcをそのスケールのすべての特性の評価の合計で割ることによって取得できます。
式3信頼できる特性の知覚された適切な値の正規化
$$p_c=\frac{qc}{\textstyle\sum_{i=1}^9 q_i}$$
表3関連性調査の質問
| 調査の質問 |
| 1.適切性の測定はどうあるべきですか? |
4.4.2.2.十分性
十分性は、「このコンテキストに対するこの特性の値はどれくらい良いか」という質問に対する答えです。十分性には、ユーザーが各特性の測定値を検討し、その値がコンテキストリスクに関してどの程度適切であるかを判断することが含まれます。
関連性の認識には確かに文脈上のリスクの考慮が含まれますが(完全に関連性のない特性が否定的な結果に寄与することは期待されないため)、十分性の認識はリスクに関する信頼性指標のより明確な評価によって特徴付けられます。より大きな認識されたリスクの下で認識された信頼性を高めるには、特定の特性に対してより高いメトリックmcが必要になりますra。十分性が高いのは、メトリックが大きいmc、または認識されているコンテキストリスクが低いraの結果である可能性があります。
したがって、知覚される十分性は、以下のように各特性について計算することができる。
式4AIの信頼できる特性の認識された十分性
$$\displaystyle s_c=\frac{m_c}{r_a}$$
表4十分性調査の質問
| 調査の質問 |
| 1. 十分性の基準はなんですか? |
| 2. Sufficiencyはどのスケールを使用しますか? |
表5リスク調査の質問
| 調査の質問 |
| 1. リスクをどのように評価しますか? |
4.5. AIとユーザーの信頼の例
図1AIとユーザーの信頼シナリオに見られるように、ユーザーuがコンテキストa内でAIシステムsと対話する場合、システムに対するユーザーの信頼はT(u、s、a)として表すことができます。 2つのAIシナリオを考えてみましょう。
まず、救命救急施設(a)の医師(u)、医療診断システム(s)(図3医療AIユーザー信頼シナリオ)
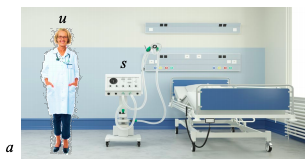
図3医療AIとユーザーの信頼シナリオ
第二に、大学のキャンパスにいる大学生(u)、音楽提案システム(s)。
(a)(図4の音楽選択AIとユーザーの信頼シナリオ)。

図5音楽選択AIとユーザーの信頼シナリオ
4.5.1. AI医療診断
4.5.1.1.医療AIとユーザーの信頼の可能性
AI医療とユーザーの信頼シナリオは、AIシステムが救命救急室で医療診断を行っているため、リスクの高い状況です(a)。医師はこの診断の受け手であり、高度に専門化された分野にいます(u)。医師はリスクの高い状況を考慮して、非常に正確な診断を受けたいと考えています。医師のユーザー信頼の可能性の要因は、次のように要約できます。
表6医療AIシステムシナリオユーザーの信頼の可能性
| 属性 | 値 |
| 人 | 思いやり(リスク回避) |
| 文化 | 西洋 |
| 年齢 | 56 |
| 性別 | 女性 |
| 技術的能力 | 低 |
| AIエクスペリエンス | 高 |
4.5.1.2.医療用AIシステムの信頼性特性の認識された関連性
表7医療用AIの信頼できる特性の認識された関連性
| 信頼できる特性 | 知覚された関連性(1-10) | 十分性の値(sc) |
| 正確さ | 9 | 0.12 |
| 信頼性 | 9 | 0.12 |
| 弾力性 | 9 | 0.12 |
| 客観性 | 3 | 0.07 |
| セキュリティ | 3 | 0.07 |
| 説明性 | 10 | 0.15 |
| 安全性 | 10 | 0.15 |
| 説明責任 | 10 | 0.15 |
| プライバシー | 2 | 0.03 |
表6の医療AIの信頼できる特性の認識された関連性が示すように、医師は説明可能性、安全性、および説明責任が最も適切であると見なします。医師がAIの決定を患者に説明する必要があり、リスクの高い環境では医師がそれぞれ全責任を負う必要があることを考えると、これらの評価は状況に応じて適切です。
「正規化された値」列は、さまざまなスケールで測定された特性が重要度のパーセンテージにどのように変換されるかを示しています。これは、式4の知覚の正規化に基づいて、例として精度を使用して以下に示されています。
信頼できる特性の適切な値:
式5医療AIシナリオの精度の認識された適切性
$$\displaystyle 0.1238=\frac{9}{65}$$
精度は、知覚される技術的信頼性の約12%を占めます。以下のグラフは、医師がシナリオに対する各特性の関連性をどのように重み付けしたかをさらに示しています。
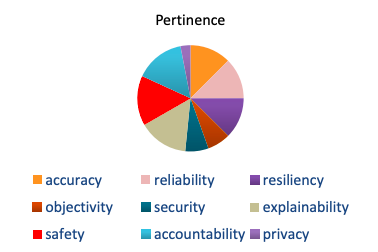
図1医療用AIシステムの信頼できる特性に対する認識された関連性
4.5.1.3.医療用AIシステムの信頼性特性の認識された十分性
各信頼性特性には、コンテキストとリスクに基づいて、その測定値が十分に良好である程度を示す十分性値があります。これらの値は、NISTのAIシステム信頼性グループによって開発されている標準とガイドラインを使用して測定されます。
ここで、1(低リスク)から10(高リスク)のスケールで評価されたコンテキストraのリスクは次のとおりです。
10:
$$\displaystyle 0.090=\frac{90\%}{10}$$
式5AIの信頼できる特性の認識された十分性に基づくと、精度の十分性の値は0.090です。
| 信頼できる特性 | 特性値(mc) | 十分性の値(sc) |
| 精度 | 90% | 0.090 |
| 信頼性 | 95% | 0.095 |
| 弾力性 | 85% | 0.085 |
| 客観性 | 100% | 0.100 |
| セキュリティ | 99% | 0.099 |
| 説明性 | 75% | 0.075 |
| 安全性 | 85% | 0.085 |
| 説明責任 | 0% | 0.00 |
| プライバシー | 80% | 0.80 |
表8医療用AIの信頼できる特性の値の認識された十分性
4.5.2. AI音楽選択シナリオ
4.5.2.1.音楽選択AIユーザーの信頼
AI音楽選択ユーザー信頼シナリオは、AIシステムが大学生がキャンパス環境でどの音楽を好むかを決定しているため、リスクの低いコンテキストです。学生は音楽の受信者であり、特定の音楽の好みを持っている可能性があります(u)。学生のユーザー信頼の可能性の要因は、次のように要約できます。
表9音楽の選択AIシステムシナリオユーザーの信頼の可能性
| 属性 | 値 |
| 人 | 冒険的な性格 |
| 文化 | 西洋 |
| 年齢 | 26 |
| 性別 | 男性 |
| 技術的能力 | 高 |
| AIエクスペリエンス | 低 |
4.5.2.2.音楽選択AIシステムの信頼性特性の認識された関連性
表10音楽選択AIシステムの信頼性特性の認識された関連性
| 信頼できる特性 | 知覚された関連性(1-10) | 十分性の値(sc) |
| 正確さ | 9 | 0.205 |
| 信頼性 | 9 | 0.205 |
| 弾力性 | 9 | 0.205 |
| 客観性 | 3 | 0.068 |
| セキュリティ | 3 | 0.068 |
| 説明性 | 2 | 0.45 |
| 安全性 | 2 | 0.45 |
| 説明責任 | 2 | 0.45 |
| プライバシー | 5 | 0.114 |
表9音楽選択AIシステムの信頼性特性の認識された関連性が示すように、学生は精度、信頼性、および復元力が最も適切であると見なします。これらの評価は、学生が好きなときに好きな音楽だけを聴き、選択が拒否されたときにシステムを適応させたいということを考えると、文脈上適切です。
「正規化された値」列は、さまざまなスケールで測定された特性が重要度のパーセンテージにどのように変換されるかを示しています。これは、式4の信頼できる特性の認識された適切な値の正規化に基づいて、例として精度を使用して以下に示されています。
式6音楽選択シナリオの精度の認識された適切性
$$\displaystyle 0.205=\frac{9}{44}$$
精度は、知覚される技術的信頼性の約21%を占めます。下のグラフは、生徒がシナリオに対する各特性の関連性をどのように重み付けしたかを示しています。
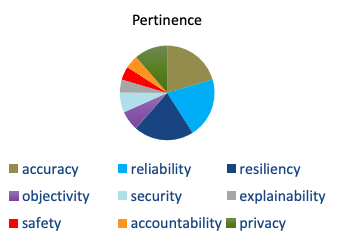
図2音楽選択の認識された関連性AIの信頼できる特性
4.5.2.3.音楽選択AIシステムの信頼性特性の認識された十分性
各信頼性特性には、コンテキストとリスクに基づいて、その測定値が十分に良好である程度を示す十分性値があります。これらの値は、NISTのAIシステム信頼性グループによって開発されている標準とガイドラインを使用して測定されます。
表11医療用AIの信頼できる特性の値の認識された十分性
| 信頼できる特性 | 特性値(mc) | 十分性の値(sc) |
| 精度 | 90% | 0.450 |
| 信頼性 | 95% | 0.475 |
| 弾力性 | 85% | 0.425 |
| 客観性 | 0% | 0.000 |
| セキュリティ | 30% | 0.150 |
| 説明性 | 2% | 0.010 |
| 安全性 | 5% | 0.025 |
| 説明責任 | 0% | 0.00 |
| プライバシー | 0% | 0.00 |
ここで、1(低リスク)から10(高リスク)のスケールで評価されたコンテキストraのリスクは次のとおりです。
2:
$$\displaystyle 0.450=\frac{90%}{2}$$
式5AIの信頼できる特性の認識された十分性に基づくと、精度の十分性の値は0.450です。
表12認識された精度の信頼性
| 知覚される精度の関連性(pc) | 正確さの値 | 知覚される 十分性(sc) |
Pc*Sc | |
| 医療シナリオ | 0.120 | 90% | 0.090 | 0.011 |
| 音楽選択シナリオ | 0.205 | 90% | 0.450 | 0.092 |
表11の認識された精度の信頼性が示すように、精度は両方のシナリオで同じ値ですが、リスクの影響は医療シナリオではるかに高くなります。間違った診断を下すことは、間違った曲を推薦することよりも重要です。リスクが低いほど、音楽シナリオでの90%の精度値の十分性が認識されます。音楽シナリオにおけるより大きな適切性は、この知覚された十分性が知覚された技術的信頼性により多く貢献することを意味します。
概要
信頼は、人間であることの明確な属性の1つです。それは私たちの限られた感覚が知覚できる情報に基づいて決定を下すことを可能にします。その人に私の電話番号を教えるべきですか?その車で目的地まで車で行かせるべきですか?私たちが私たちの生活を送ることを可能にするのは信頼です。テクノロジーは私たちの職業的および個人的な生活の多くの側面に浸透し続けています。さらに、システムはより複雑になっています。複雑さを軽減するメカニズムである信頼は、私たちのテクノロジーについての知識が少ないほど、さらに重要になります。 AIへの信頼を理解するためには、このように技術が複雑になっているため、ユーザーの視点に目を向ける必要があります。
AIへの信頼は、人間のユーザーがシステムをどのように認識するかに依存します。このホワイトペーパーは、AIシステムの信頼性に関して行われている作業を補完することを目的としています。 AIシステムに高いレベルの技術的信頼性があり、信頼性特性の値が使用のコンテキスト、特にそのコンテキストに固有のリスクに対して十分であると認識される場合、AIユーザーの信頼の可能性が高まります。人間とAIの共同作業に必要なのは、ユーザーの認識に基づくこの信頼です。
このホワイトペーパーのアプローチで直面する多くの課題があります。 表12AIユーザー信頼調査の質問にあるものから始めて、人がAIを信頼できるようにするものを深く掘り下げるにつれて、さらに多くの課題が発生します。 他の人間の認知プロセスと同様に、信頼は複雑で非常に文脈に依存しますが、これらの信頼要因を調査することにより、人口の大部分がこの有望なテクノロジーを使用および受け入れることができるようになります。
表13AIとユーザーの信頼の調査に関する質問
| 調査課題 |
| ユーザーの信頼の可能性 |
| 1. ユーザーの信頼の可能性を定義する一連の属性は何ですか? |
| ユーザーの信頼に対する UX の影響 |
| 2. ユーザーの信頼に影響を与えるユーザー体験の指標は? |
| 3. ユーザー体験の指標はユーザーの信頼にどのように影響しますか? |
| 関連性 |
| 4. 妥当性を測るためには何を測定すべきか |
| 十分性 |
| 5. 十分性の基準は何ですか? |
| 6. 十分性はどの尺度を使用しますか? |
| リスク |
| 7. リスクをどのように評価しますか? |
6.引用された著作物
[1] N. Luhmann, “Defining the Problem: Social Complexity,” in Trust and Power, John Wiley & Sons, 1979, pp. 5 – 11.
[2] S. Kaya, “Outgroup Predjudice from an Evolutionary Perspective: Survey Evidence from Europe,” Journal of International and Global Studies, 2015.
[3] S. E. Taylor, The Tending Instinct: How nuturing is essential to who we are and how we live, NY: Harry Holt & Company LLC, 2002.
[4] Macy and Skvoretz, 1998.
[5] K. Sedar, 2015.
[6] Axelrod and Hamilton, Journal of International and Global Studfies, 1981.
[7] D. Kahneman, “A Bias to Believe and Confirm,” in Think Fast and Slow, New
York, Farrar, Straus and Giroux, 2011, pp. 80-85.
[8] R. Mayo, “Cognition is a Matter Of Trust: Distrust Tunes Cognitive Processes,” European Review of Social Psychology, pp. 283-327, 2015.
[9] R. Mayo, D. Alfasi and N. Schwarz, “Distrust and the positive test heuristic:
Dispositional and situated social distrust improves performance on the Wason Rule Discovery Task,” Journal of Experimental Psychology: General, vol. 143, no. 3, pp. 985 – 990, 2014.
[10] Y. Schul, R. Mayo and E. Burnstein, “Encoding Under Trust and Distrust: The Spontaneous Activation of Incongruent Cognition,” Journal of Personality and Social Psychology, 2004.
[11] C. A. Hill and E. A. O’Hara, “A Cognitive Theory of Trust,” Washinngton
University Law Review, pp. 1717-1796, 2006.
[12] M. G. Haselton, D. Nettle and D. R. Murrary, “The evolution of cognitive bias,”
Than Handbook of Evolutionary Psychology, pp. 1-20, 2015.
[13] N. Luhmann, “Trust and Distrust,” in Trust and Power, John Wiley & Sons, 1979, pp. 79-85.
[14] R. J. Lewicki, D. J. McAllister and R. J. Bies, “Trust and Distrust: New
Relationships and Realities,” Academy of Management Review, pp. 438-458, 1998.
[15] D. Gambetta, “Can we Trust Trust,” in Trust: Making and Breaking Cooperative Relations, 2000, pp. 213-237.
[16] R. C. Mayer, J. H. Davis and F. D. Schoorman, “An Integrative Model of
Organizational Trust,” Acamdemy of Management Review, pp. 709-734, 1995.
[17] J. B. Rotter, “Interpersonal trust, trustworthiness, and gullibility,” American Psychologist, vol. 35, no. 1, pp. 1 – 7, 1980.
[18] J. K. Rempel, J. G. Holmes and M. P. Zanna, “Trust in close relationships.,”
Journal of Personality and Social Psychology, vol. 49, no. 1, pp. 95-112, 1985.
[19] L. Becker, “Trust as noncognitive security about motives,” Ethics, vol. 107, no. 1, pp. 43-61, 1996.
[20] B. Reeves and C. I. Nass, The media equation: How people treat computers,
television, and new media like real people and places, Cambridge University Press, 1996.
[21] C. Nass, J. Steuer and E. R. Tauber, “Computers are social actors,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 1994.
[22] C. Nass, Y. Moon and N. Green, “Are machines gender neutral? Gender‐stereotypic responses to computers with voices.,” Journal of Applied Social Psychology, vol. 27, no. 10, pp. 864 – 876, 1997.
[23] Y. Moon, “Intimate exchanges: Using computers to elicit self-disclosure from consumers,” Journal of Consumer Research, vol. 26, no. 4, pp. 323 – 339, 2000.
[24] C. Nass and Y. Moon, “Machines and mindlessness: Social responses to
computers,” Journal of Social Issues, vol. 56, no. 1, pp. 81 – 103, 2000.
[25] B. Muir, “Trust in Automation: Part 1. Theoretical Issues in the study of trust and human intervention in automated systems,” Ergonomics, vol. 37, no. 11, pp. 1905-1922, 1994.
[26] B. M. Muir and N. Moray, “Trust in Automation Part II. Experimental studies of trust and human intervention in a process control simulation,” Ergonomics, vol. 39, no. 3, pp. 429-460, 1996.
[27] K. A. Hoff and M. Bashir, “Trust in automation: Integrating empirical evidence on factors that influence trust,” Human Factors, vol. 57, no. 3, pp. 407-434, 2006.
[28] J. D. Lee and K. A. See, “Trust in automation: Designing for appropriate reliance,” Human Factors, vol. 46, no. 1, pp. 50-80, 2004.
[29] P. Madhavan and D. A. Wiegmann, “Simularities and differences between humanhuman and human-automation trust: an integrative review.,” Theoretical Issues in Ergonomics Science, vol. 8, no. 4, pp. 277-301, 2007.
[30] E. J. De Visser, S. S. Monfort, R. McKendrick, M. A. Smith, P. E. McKnight, F.
Krueger and R. Parasuraman, “Almost human: Anthropomorphism increases trust resilience in cognitive agents,” Journal of Experimental Psychology: Applied, vol. 22, no. 3, pp. 331 – 349, 2016.
[31] “Bill Gates: Trustworthy Computing,” 17 Janurary 2002. [Online]. Available: https://www.wired.com/2002/01/bill-gates-trustworthy-computing/.
[32] WIRED, 2002. [Online]. Available: Https://www.wired,com/2002/bill-gatestrustworthy-computing/. [Accessed August 2019].
[33] IEEE, 982.1-2005 Standard Dictionary of Measures of the Software Aspects of Dependability, IEEE, 2005.
[34] ISO/IEC/IEEE, 15206-1:2019 Systems and software engineering – systems and software assurance, Part 1: Concepts and vocabulary, ISO/IEC/IEEE, 2019.
[35] B. M. Muir, “Trust in automation: Part I. Theoretical issues in the study of trust and human intervention in automated systems,” Ergonomics, vol. 37, no. 11, pp. 1905 – 1922, 1994.
[36] National Institute of Standards and Technology, “US LEADERSHIP IN AI: A Plan for Federal Engagement in Developing Technical Syandards and Related Tools, Prepared in response to Excutive Order 13859,” 2019.
[37] P. L. McDermott and R. N. ten Brink, “Practical Guidance for Evaluating
Calibrated Trust,” in Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Los Angeles, CA, 2019.
[38] T. Tullis and B. Albert, Measuring the User Experience 2nd Edition, Waltham: Morgan Kaufmann, 2013.
[39] B. Skyrms, “Trust, Risk, and the Social Contract,” Synthese, pp. 21-25, 2008.
[40] Y. Schul and E. Burnstein, “Encoding under trust and distrust: the spontaneous activation of incongruent cognitions,” Journal of Personality and Social Psychology, 2004.
[41] J. Sauro and J. Lewis, Quantifying the User Experience, Cambridge: Morgan
Kaufmann, 2016.
[42] J. Sauro and E. Kindlund, “Amethod to standardize usability metrics into a single score,” in Proceedings of CHI 2005, Portland, 2005.
[43] M. Mohtashemi and L. Mui, “Evolution of indirect reciprocity by social
information: the role of trust and reputation in evolution of altruism,” Journal of Theorical Biology, pp. 523-531, 2003.
[44] M. W. Macy and J. Skvoretz, “The evolution of Trust and Cooperation Between Strangers: A Computational Model,” American Sociological Review, pp. 638-660, 1998.
[45] B. Barber, The Logic and Limits of Trust, Rutgers University Press, 1983.
[46] R. Axelrod and W. D. Hamilton, “The Evolution of Cooperation,” Science, pp. 1390-1396, 1981.
[47] ISO/IEC/IEEEE 15026-1:2019, 2019.
[48] International Organization for Standardization TC/ 159/ SC 4, ISO 9241-11:2018 Ergonomics of human-system interaction — Part 11: Usability: Definitions and concepts, Geneva: International Organization for Standardization, 2018.
[49] S. Kaya, “Outgroup Prejudice from an Evolutionary Perspective: Survey Evidence from Europe,” Journal of International and Global Studies, 2015.
Appendix A AI User Trust Equations